Hi,community,
Recently our team did some comparative test of CarbonData and parquet. We choose spark2.1 as the upper-layer processing engine, and the total row number of test data is 200 billion.
EnvironmentBelow is the testing environment infomation:
> Number of nodes: 10, CPU: 48cores, memory: 256G
> Spark Version: 2.1.0, Hadoop Version: 2.7.2, CarbonData 1.0
Test dataOur test data is similar to the telecom operation data. One typical characteristic of this kind of data is that all of its columns are dimension columns.
> number of rows: 200 billion
> carbonfile: 13T
> parquetfile: 13T
Test casesquery-1: create table t01 using parquet select * from data_200b where fi='xxx' distribute by fs;
query-2: create table t02 using parquet select fa from data_200b where fi='xxx' distribute by fs;
query-3: create table t03 using parquet select * from data_200b where fs in('xx1','xx2','xx3','xx4','xx5',...) distribute by fp;
query-4: create table t04 using parquet as select fi,count(*) cnt from data_200b group by fi;
query-5: create table t05 using parquet as select * from data_200b where fi like 'xx%' distribute by fs;
query-6: create table t06 using parquet as select * from data_200b where fi like '%xx' distribute by fs;
query-7: create table t07 using parquet as select t1.* from data_200b t1 inner join data_100th t2 on (t1.fi=t2.fi);
query-8: create table t08 select distinct fi from data_200b;
The fields used in test cases(fi,fs,fp) are string type and fp is the first column. "distribute by " segment is added to avoid generating too much result files.
Result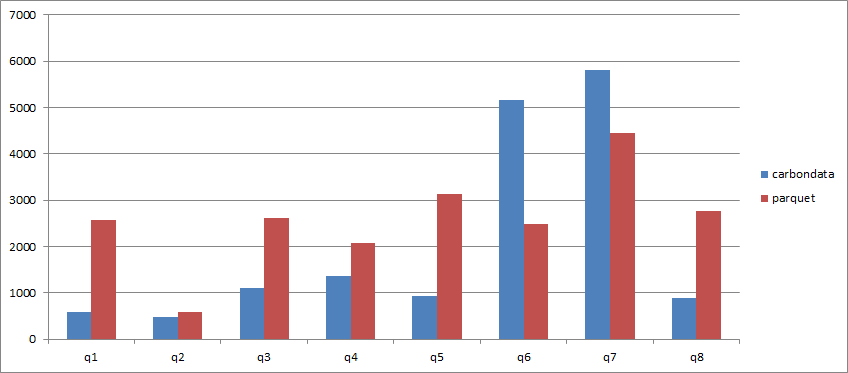
As illustrated in the picture above, in most listed scenarios, CarbonData format has several times better performance than Parquet format. The exceptions are scenarios of the "like '%xxx'"(query-6) and join(query-7).
We tested CarbonData0.2 before and found it has serious GC issues in some scenarios. Overall, performance of CarbonData0.2 didn't meet our expectations at that time. But CarbonData1.0 has been significantly enhanced in many aspects which is proved by our test.
Now we are migrating part of our bussiness to CarbonData and will doing more test on other features such as updating, deleting, compaction. Also we are very interested in new features which are still in progress such as interface for statistics and partition.

