【DISCUSS】add more index for sort columns


|
hi all
Carbon will add min/max index for sort columns which used for better filter query. So can we add more index for the sort column to make filter faster. This is one idea which I get from anther database design. For example this is one student, and the column: score in the student table which will be sorted column. And the score range is from 1 to 100. The table as following:
So for the query as following will take all the block data. query1:select sum(score) from student when score score > 90 query2:select sum(score) from student when score score > 60 and score < 70. Following two suggestion to reduce the block scan. Suggestion 1: according the score range to divide into multiple small range for example 4:  0: meas this block has not the score rang value 1: meas this block has the score rang value If add this index, for the query1 only need scan 1/4 data of the block and query2 no need scan any data, directly sckip this block Suggestion 2: record more min/max for the score, for example every 5 rows record one min/max 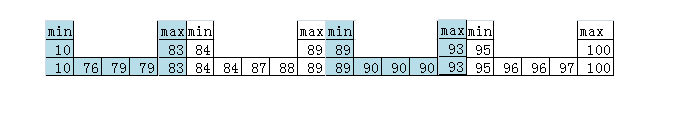 If add this index for query1 only need scan 1/2 data of the block and query2 only need scan 1/4 data of the block this is the raw idea, please Jacky, Ravindra and liang correct it whether we can add this feature. thanks Regards Bill |
Re: 【DISCUSS】add more index for sort columns
|
|
Hi Bill,
Min/max for measure columns are already added in V3 format. Now measure columns filters are being added now so it does block and blocklet pruning based on min/max to reduce IO and processing. And as per your suggestions, column need to be sorted and maintain multiple ranges in metadata. But if the data is sorted we can do binary search and find out the data directly we may not require to maintain ranges in this case. If the data is not sorted then maintain more min/max may give some benefit. This approach we can take as alternate approach for inverted indexes. Regards, Ravindra. On Tue, Mar 14, 2017, 20:40 bill.zhou <[hidden email]> wrote: > hi all > > Carbon will add min/max index for sort columns which used for better > filter query. So can we add more index for the sort column to make filter > faster. > > This is one idea which I get from anther database design. > For example this is one student, and the column: score in the student > table which will be sorted column. And the score range is from 1 to 100. > The table as following: > > id name score > 1 bill001 83 > 2 bill002 84 > 3 bill003 90 > 4 bill004 89 > 5 bill005 93 > 6 bill006 76 > 7 bill007 87 > 8 bill008 90 > 9 bill009 89 > 10 bill010 96 > 11 bill011 96 > 12 bill012 100 > 13 bill013 84 > 14 bill014 90 > 15 bill015 79 > 16 bill016 1 > 17 bill017 97 > 18 bill018 79 > 19 bill019 88 > 20 bill068 95 > > After load the data into Cabron the score column will sort as following: > 1 76 79 79 83 84 84 87 88 > 89 89 90 90 90 93 95 96 96 97 > 100 > > the min/max index is 1/100. > So for the query as following will take all the block data. > query1:select sum(score) from student when score score > 90 > query2:select sum(score) from student when score score > 60 and score < 70. > > Following two suggestion to reduce the block scan. > Suggestion 1: according the score range to divide into multiple small range > for example 4: > < > http://apache-carbondata-mailing-list-archive.1130556.n5.nabble.com/file/n8891/index1.png > > > 0: meas this block has not the score rang value > 1: meas this block has the score rang value > If add this index, for the query1 only need scan 1/4 data of the block and > query2 no need scan any data, directly sckip this block > > Suggestion 2: record more min/max for the score, for example every 5 rows > record one min/max > < > http://apache-carbondata-mailing-list-archive.1130556.n5.nabble.com/file/n8891/index2.png > > > If add this index for query1 only need scan 1/2 data of the block and > query2 > only need scan 1/4 data of the block > > this is the raw idea, please Jacky, Ravindra and liang correct it whether > we > can add this feature. thanks > > Regards > Bill > > > > > -- > View this message in context: > http://apache-carbondata-mailing-list-archive.1130556.n5.nabble.com/DISCUSS-add-more-index-for-sort-columns-tp8891.html > Sent from the Apache CarbonData Mailing List archive mailing list archive > at Nabble.com. > |
«
Return to Apache CarbonData Dev Mailing List archive
|
1 view|%1 views
| Free forum by Nabble | Edit this page |