1. many places use the function 'getNumOfCores' of CarbonProperties which
returns the loading cores.
2. so if we still use the value in scene like 'query' or 'compaction' , it
will be confused.
and i start the pr 2907 <
https://github.com/apache/carbondata/pull/2907>
when loading data,the loading cores will be changed not the default value if
the property 'carbon.number.of.cores.while.loading' unset, and the value
will be set in CarbonProperties which is singleton, the code:
// get the value of 'spark.executor.cores' from spark conf, default
value is 1
val sparkExecutorCores =
sparkSession.sparkContext.conf.get("spark.executor.cores", "1")
// get the value of 'carbon.number.of.cores.while.loading' from carbon
properties,
// default value is the value of 'spark.executor.cores'
val numCoresLoading =
try {
CarbonProperties.getInstance()
.getProperty(CarbonCommonConstants.NUM_CORES_LOADING,
sparkExecutorCores)
} catch {
case exc: NumberFormatException =>
LOGGER.error("Configured value for property " +
CarbonCommonConstants.NUM_CORES_LOADING
+ " is wrong. Falling back to the default value "
+ sparkExecutorCores)
sparkExecutorCores
}
// update the property with new value
carbonProperty.addProperty(CarbonCommonConstants.NUM_CORES_LOADING,
numCoresLoading)
so the description in the document for 'carbon.number.of.cores.while.loading' is wrong:
carbon document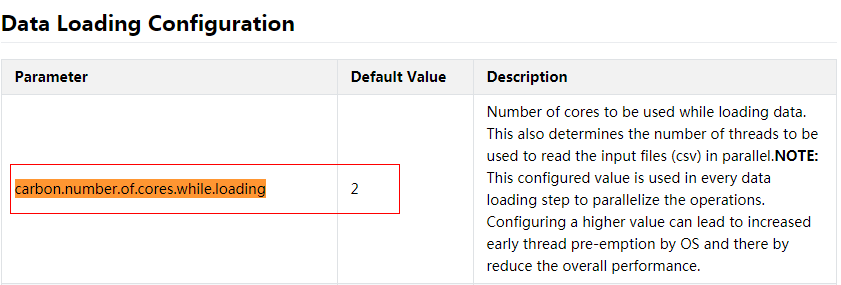
and the value 'cores' of compation or partition should be dealed with the
same using 'spark.executor.cores'?
--
Sent from:
http://apache-carbondata-dev-mailing-list-archive.1130556.n5.nabble.com/

