Optimize Order By + Limit Query


|
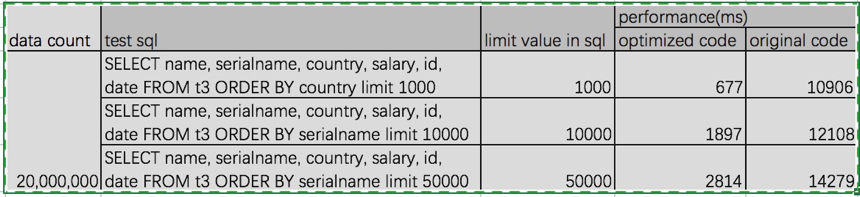
Hi Carbon Dev, Currently I have done optimization for ordering by 1 dimension. my local performance test as below. Please give your suggestion.
my optimization solution for order by 1 dimension + limit as below mainly filter some unnecessary blocklets and leverage the dimension's order stored feature to get sorted data in each partition. at last use the TakeOrderedAndProject to merge sorted data from partitions step1. change logical plan and push down the order by and limit information to carbon scan and change sort physical plan to TakeOrderedAndProject since data will be get and sorted in each partition step2. in each partition apply the limit number, blocklet's min_max index to filter blocklet. it can reduce scan data if some blocklets were filtered for example, SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000 supposing there are 2 blocklets , each has 32000 data, serial name is between serialname1 to serialname2 in the first blocklet and between serialname2 to serialname3 in the second blocklet. Actually we only need to scan the first blocklet since 32000 > 100 and first blocklet's serial name <= second blocklet's serial name
step3. load the order by dimension data to scanResult. put all scanResults to a TreeSet for sorting Other columns' data will be lazy-loaded in step4. step4. according to the limit value, use a iterator to get the topN sorted data from the TreeSet. In the same time to load other columns data if needed. in this step it tries to reduce scanning non-sort dimension data. for example, SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000 supposing there are 3 blocklets , in the first 2 blocklets, serial name is between serialname1 to serialname100 and each has 2500 serialname1 and serialname2. In the third blocklet, serial name is between serialname2 to serialnam100, but no serialname1 in it. load serial name data for the 3 blocklets and put all to a treeset sorting by the min serialname. apparently use iterator to get the top 10000 sorted data, it only need to care the first 2 blocklets(5000 serialname1 + 5000 serialname2). In others words, it loads serial name data for the 3 blocklets.But only "load name, country, salary, id, date"'s data for the first 2 blocklets
step5. TakeOrderedAndProject physical plan will be used to merge sorted data from partitions
the below items also can be optimized in future
• leverage mdk keys' order feature to optimize the SQL who order by prefix dimension columns of MDK • use the dimension order feature in blocklet lever and dimensions' inverted index to optimize SQL who order by multi-dimensions
Jarck Ma
|
||||||||||||||||||||
Re: Optimize Order By + Limit Query
|
|
Hi Jarck Ma, It is great to try optimizing Carbondata. We used to have multiple push down optimizations from spark to carbon like aggregation, limit, topn etc. But later it was removed because it is very hard to maintain for version to version. I feel it is better that execution engine like spark can do these type of operations. Regards, On Tue, Mar 28, 2017, 14:28 马云 <[hidden email]> wrote:
|
||||||||||||||||||||
Re:Re: Optimize Order By + Limit Query
|
|
Hi Ravindran,
Thanks for your quick response. please see my answer as below >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> What if the order by column is not the first column? It needs to scan all blocklets to get the data out of it if the order by column is not first column of mdk >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Answer : if step2 doesn't filter any blocklet, you are right,It needs to scan all blocklets to get the data out of it if the order by column is not first column of mdk but it just scan all the order by column's data, for others columns data, use the lazy-load strategy and it can reduce scan accordingly to limit value. Hence you can see the performance is much better now after my optimization. Currently the carbondata order by + limit performance is very bad since it scans all data. in my test there are 20,000,000 data, it takes more than 10s, if data is much more huge, I think it is hard for user to stand such bad performance when they do order by + limit query? >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> We used to have multiple push down optimizations from spark to carbon like aggregation, limit, topn etc. But later it was removed because it is very hard to maintain for version to version. I feel it is better that execution engine like spark can do these type of operations. >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Answer : In my opinion, I don't think "hard to maintain for version to version" is a good reason to give up the order by + limit optimization. I think it can create new class to extends current and try to reduce the impact for the current code. Maybe can make it is easy to maintain. Maybe I am wrong. At 2017-03-29 02:21:58, "Ravindra Pesala" <[hidden email]> wrote: Hi Jarck Ma, It is great to try optimizing Carbondata. I think this solution comes up with many limitations. What if the order by column is not the first column? It needs to scan all blocklets to get the data out of it if the order by column is not first column of mdk. We used to have multiple push down optimizations from spark to carbon like aggregation, limit, topn etc. But later it was removed because it is very hard to maintain for version to version. I feel it is better that execution engine like spark can do these type of operations. Regards, Ravindra. On Tue, Mar 28, 2017, 14:28 马云 <[hidden email]> wrote: Hi Carbon Dev, Currently I have done optimization for ordering by 1 dimension. my local performance test as below. Please give your suggestion. | data count | test sql | limit value in sql | performance(ms) | | optimized code | original code | | 20,000,000 | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY country limit 1000 | 1000 | 677 | 10906 | | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000 | 10000 | 1897 | 12108 | | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 50000 | 50000 | 2814 | 14279 | my optimization solution for order by 1 dimension + limit as below mainly filter some unnecessary blocklets and leverage the dimension's order stored feature to get sorted data in each partition. at last use the TakeOrderedAndProject to merge sorted data from partitions step1. change logical plan and push down the order by and limit information to carbon scan and change sort physical plan to TakeOrderedAndProject since data will be get and sorted in each partition step2. in each partition apply the limit number, blocklet's min_max index to filter blocklet. it can reduce scan data if some blocklets were filtered for example, SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000 supposing there are 2 blocklets , each has 32000 data, serial name is between serialname1 to serialname2 in the first blocklet and between serialname2 to serialname3 in the second blocklet. Actually we only need to scan the first blocklet since 32000 > 100 and first blocklet's serial name <= second blocklet's serial name step3. load the order by dimension data to scanResult. put all scanResults to a TreeSet for sorting Other columns' data will be lazy-loaded in step4. step4. according to the limit value, use a iterator to get the topN sorted data from the TreeSet. In the same time to load other columns data if needed. in this step it tries to reduce scanning non-sort dimension data. for example, SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000 supposing there are 3 blocklets , in the first 2 blocklets, serial name is between serialname1 to serialname100 and each has 2500 serialname1 and serialname2. In the third blocklet, serial name is between serialname2 to serialnam100, but no serialname1 in it. load serial name data for the 3 blocklets and put all to a treeset sorting by the min serialname. apparently use iterator to get the top 10000 sorted data, it only need to care the first 2 blocklets(5000 serialname1 + 5000 serialname2). In others words, it loads serial name data for the 3 blocklets.But only "load name, country, salary, id, date"'s data for the first 2 blocklets step5. TakeOrderedAndProject physical plan will be used to merge sorted data from partitions the below items also can be optimized in future • leverage mdk keys' order feature to optimize the SQL who order by prefix dimension columns of MDK • use the dimension order feature in blocklet lever and dimensions' inverted index to optimize SQL who order by multi-dimensions Jarck Ma |
Re: Re: Optimize Order By + Limit Query
|
|
Hi,
You mean Carbon do the sorting if the order by column is not first column and provide only limit values to spark. But the same job spark is also doing it just sorts the partition and gets the top values out of it. You can reduce the table_blocksize to get the better sort performance as spark try to do sorting inside memory. I can see we can do some optimizations in integration layer itself with out pushing down any logic to carbon like if the order by column is first column then we can just get limit values with out sorting any data. Regards, Ravindra. On 29 March 2017 at 08:58, 马云 <[hidden email]> wrote: > Hi Ravindran, > Thanks for your quick response. please see my answer as below > >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > What if the order by column is not the first column? It needs to scan all > blocklets to get the data out of it if the order by column is not first > column of mdk > >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > Answer : if step2 doesn't filter any blocklet, you are right,It needs to > scan all blocklets to get the data out of it if the order by column is not > first column of mdk > but it just scan all the order by column's data, for > others columns data, use the lazy-load strategy and it can reduce scan > accordingly to limit value. > Hence you can see the performance is much better now > after my optimization. Currently the carbondata order by + limit > performance is very bad since it scans all data. > in my test there are 20,000,000 data, it takes more than > 10s, if data is much more huge, I think it is hard for user to stand such > bad performance when they do order by + limit query? > > > >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > We used to have multiple push down optimizations from spark to carbon > like aggregation, limit, topn etc. But later it was removed because it is > very hard to maintain for version to version. I feel it is better that > execution engine like spark can do these type of operations. > >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > Answer : In my opinion, I don't think "hard to maintain for version to > version" is a good reason to give up the order by + limit optimization. > I think it can create new class to extends current and try to reduce the > impact for the current code. Maybe can make it is easy to maintain. > Maybe I am wrong. > > > > > At 2017-03-29 02:21:58, "Ravindra Pesala" <[hidden email]> wrote: > > > Hi Jarck Ma, > > It is great to try optimizing Carbondata. > I think this solution comes up with many limitations. What if the order by > column is not the first column? It needs to scan all blocklets to get the > data out of it if the order by column is not first column of mdk. > > We used to have multiple push down optimizations from spark to carbon like > aggregation, limit, topn etc. But later it was removed because it is very > hard to maintain for version to version. I feel it is better that execution > engine like spark can do these type of operations. > > > Regards, > Ravindra. > > > > On Tue, Mar 28, 2017, 14:28 马云 <[hidden email]> wrote: > > > Hi Carbon Dev, > > Currently I have done optimization for ordering by 1 dimension. > > my local performance test as below. Please give your suggestion. > > > > > | data count | test sql | limit value in sql | performance(ms) | > | optimized code | original code | > | 20,000,000 | SELECT name, serialname, country, salary, id, date FROM t3 > ORDER BY country limit 1000 | 1000 | 677 | 10906 | > | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY > serialname limit 10000 | 10000 | 1897 | 12108 | > | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY > serialname limit 50000 | 50000 | 2814 | 14279 | > > my optimization solution for order by 1 dimension + limit as below > > mainly filter some unnecessary blocklets and leverage the dimension's > order stored feature to get sorted data in each partition. > > at last use the TakeOrderedAndProject to merge sorted data from partitions > > step1. change logical plan and push down the order by and limit > information to carbon scan > > and change sort physical plan to TakeOrderedAndProject since > data will be get and sorted in each partition > > step2. in each partition apply the limit number, blocklet's min_max index > to filter blocklet. > > it can reduce scan data if some blocklets were filtered > > for example, SELECT name, serialname, country, salary, id, date > FROM t3 ORDER BY serialname limit 10000 > > supposing there are 2 blocklets , each has 32000 data, serial name is > between serialname1 to serialname2 in the first blocklet > > and between serialname2 to serialname3 in the second blocklet. Actually > we only need to scan the first blocklet > > since 32000 > 100 and first blocklet's serial name <= second blocklet's > serial name > > > > step3. load the order by dimension data to scanResult. put all > scanResults to a TreeSet for sorting > > Other columns' data will be lazy-loaded in step4. > > step4. according to the limit value, use a iterator to get the topN sorted > data from the TreeSet. In the same time to load other columns data if > needed. > > in this step it tries to reduce scanning non-sort dimension > data. > > for example, SELECT name, serialname, country, salary, id, date > FROM t3 ORDER BY serialname limit 10000 > > supposing there are 3 blocklets , in the first 2 blocklets, serial name > is between serialname1 to serialname100 and each has 2500 serialname1 and > serialname2. > > In the third blocklet, serial name is between serialname2 to > serialnam100, but no serialname1 in it. > > load serial name data for the 3 blocklets and put all to a treeset sorting > by the min serialname. > > apparently use iterator to get the top 10000 sorted data, it only need to > care the first 2 blocklets(5000 serialname1 + 5000 serialname2). > > In others words, it loads serial name data for the 3 blocklets.But only > "load name, country, salary, id, date"'s data for the first 2 blocklets > > > > step5. TakeOrderedAndProject physical plan will be used to merge sorted > data from partitions > > > > the below items also can be optimized in future > > > > • leverage mdk keys' order feature to optimize the SQL who order by > prefix dimension columns of MDK > > • use the dimension order feature in blocklet lever and dimensions' > inverted index to optimize SQL who order by multi-dimensions > > > > > > > > > > > > Jarck Ma > > > > > > > > > -- Thanks & Regards, Ravi |
Re:Re: Re: Optimize Order By + Limit Query
|
|
This post was updated on .
Hi Ravindran,
yes, use carbon do the sorting if the order by column is not first column.But its sorting is very high since the dimension data in blocklet is stored after sorting.So in carbon can use merge sort + topN to get N data from each block.In addition, the biggest difference is that it can reduce disk IO since can use limit n to reduce required blocklets.if you only apply spark's top N, I don't think you can make suck below performance. That's impossible if don't reduce disk IO. 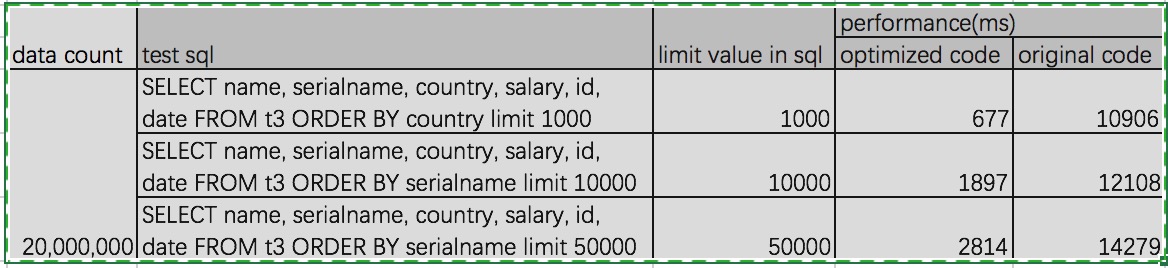 At 2017-03-30 03:12:54, "Ravindra Pesala" <ravi.pesala@gmail.com> wrote: >Hi, > >You mean Carbon do the sorting if the order by column is not first column >and provide only limit values to spark. But the same job spark is also >doing it just sorts the partition and gets the top values out of it. You >can reduce the table_blocksize to get the better sort performance as spark >try to do sorting inside memory. > >I can see we can do some optimizations in integration layer itself with out >pushing down any logic to carbon like if the order by column is first >column then we can just get limit values with out sorting any data. > >Regards, >Ravindra. > >On 29 March 2017 at 08:58, 马云 <simafengyun1984@163.com> wrote: > >> Hi Ravindran, >> Thanks for your quick response. please see my answer as below >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> >> What if the order by column is not the first column? It needs to scan all >> blocklets to get the data out of it if the order by column is not first >> column of mdk >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> >> Answer : if step2 doesn't filter any blocklet, you are right,It needs to >> scan all blocklets to get the data out of it if the order by column is not >> first column of mdk >> but it just scan all the order by column's data, for >> others columns data, use the lazy-load strategy and it can reduce scan >> accordingly to limit value. >> Hence you can see the performance is much better now >> after my optimization. Currently the carbondata order by + limit >> performance is very bad since it scans all data. >> in my test there are 20,000,000 data, it takes more than >> 10s, if data is much more huge, I think it is hard for user to stand such >> bad performance when they do order by + limit query? >> >> >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> >> We used to have multiple push down optimizations from spark to carbon >> like aggregation, limit, topn etc. But later it was removed because it is >> very hard to maintain for version to version. I feel it is better that >> execution engine like spark can do these type of operations. >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> >> Answer : In my opinion, I don't think "hard to maintain for version to >> version" is a good reason to give up the order by + limit optimization. >> I think it can create new class to extends current and try to reduce the >> impact for the current code. Maybe can make it is easy to maintain. >> Maybe I am wrong. >> >> >> >> >> At 2017-03-29 02:21:58, "Ravindra Pesala" <ravi.pesala@gmail.com> wrote: >> >> >> Hi Jarck Ma, >> >> It is great to try optimizing Carbondata. >> I think this solution comes up with many limitations. What if the order by >> column is not the first column? It needs to scan all blocklets to get the >> data out of it if the order by column is not first column of mdk. >> >> We used to have multiple push down optimizations from spark to carbon like >> aggregation, limit, topn etc. But later it was removed because it is very >> hard to maintain for version to version. I feel it is better that execution >> engine like spark can do these type of operations. >> >> >> Regards, >> Ravindra. >> >> >> >> On Tue, Mar 28, 2017, 14:28 马云 <simafengyun1984@163.com> wrote: >> >> >> Hi Carbon Dev, >> >> Currently I have done optimization for ordering by 1 dimension. >> >> my local performance test as below. Please give your suggestion. >> >> >> >> >> | data count | test sql | limit value in sql | performance(ms) | >> | optimized code | original code | >> | 20,000,000 | SELECT name, serialname, country, salary, id, date FROM t3 >> ORDER BY country limit 1000 | 1000 | 677 | 10906 | >> | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY >> serialname limit 10000 | 10000 | 1897 | 12108 | >> | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY >> serialname limit 50000 | 50000 | 2814 | 14279 | >> >> my optimization solution for order by 1 dimension + limit as below >> >> mainly filter some unnecessary blocklets and leverage the dimension's >> order stored feature to get sorted data in each partition. >> >> at last use the TakeOrderedAndProject to merge sorted data from partitions >> >> step1. change logical plan and push down the order by and limit >> information to carbon scan >> >> and change sort physical plan to TakeOrderedAndProject since >> data will be get and sorted in each partition >> >> step2. in each partition apply the limit number, blocklet's min_max index >> to filter blocklet. >> >> it can reduce scan data if some blocklets were filtered >> >> for example, SELECT name, serialname, country, salary, id, date >> FROM t3 ORDER BY serialname limit 10000 >> >> supposing there are 2 blocklets , each has 32000 data, serial name is >> between serialname1 to serialname2 in the first blocklet >> >> and between serialname2 to serialname3 in the second blocklet. Actually >> we only need to scan the first blocklet >> >> since 32000 > 100 and first blocklet's serial name <= second blocklet's >> serial name >> >> >> >> step3. load the order by dimension data to scanResult. put all >> scanResults to a TreeSet for sorting >> >> Other columns' data will be lazy-loaded in step4. >> >> step4. according to the limit value, use a iterator to get the topN sorted >> data from the TreeSet. In the same time to load other columns data if >> needed. >> >> in this step it tries to reduce scanning non-sort dimension >> data. >> >> for example, SELECT name, serialname, country, salary, id, date >> FROM t3 ORDER BY serialname limit 10000 >> >> supposing there are 3 blocklets , in the first 2 blocklets, serial name >> is between serialname1 to serialname100 and each has 2500 serialname1 and >> serialname2. >> >> In the third blocklet, serial name is between serialname2 to >> serialnam100, but no serialname1 in it. >> >> load serial name data for the 3 blocklets and put all to a treeset sorting >> by the min serialname. >> >> apparently use iterator to get the top 10000 sorted data, it only need to >> care the first 2 blocklets(5000 serialname1 + 5000 serialname2). >> >> In others words, it loads serial name data for the 3 blocklets.But only >> "load name, country, salary, id, date"'s data for the first 2 blocklets >> >> >> >> step5. TakeOrderedAndProject physical plan will be used to merge sorted >> data from partitions >> >> >> >> the below items also can be optimized in future >> >> >> >> • leverage mdk keys' order feature to optimize the SQL who order by >> prefix dimension columns of MDK >> >> • use the dimension order feature in blocklet lever and dimensions' >> inverted index to optimize SQL who order by multi-dimensions >> >> >> >> >> >> >> >> >> >> >> >> Jarck Ma >> >> >> >> >> >> >> >> >> > > > >-- >Thanks & Regards, >Ravi |
Re: Re: Re: Optimize Order By + Limit Query
|
|
Hi,
It comes up with many limitations 1. It cannot work for dictionary columns. As there is no guarantee that dictionary allocation is in sorted order. 2. It cannot work for no inverted index columns. 3. It cannot work for measures. Moreover as you mentioned that it can reduce IO, But I don't think we can reduce any IO since we need to read all blocklets to do merge sort. And I am not sure how we can keep all the data in memory until we do merge sort. I am still believe that this work is belonged to execution engine, not file format. This type of specific improvements may give good performance in some specific type of queries but these will give long term complications in maintainability. Regards, Ravindra. On 30 March 2017 at 08:23, 马云 <[hidden email]> wrote: > Hi Ravindran, > > yes, use carbon do the sorting if the order by column is not first column. > > But its sorting is very high since the dimension data in blocklet is stored after sorting. > > So in carbon can use merge sort + topN to get N data from each block. > > In addition, the biggest difference is that it can reduce disk IO since can use limit n to reduce required blocklets. > > if you only apply spark's top N, I don't think you can make suck below performance. > > That's impossible if don't reduce disk IO. > > > > > > > > > At 2017-03-30 03:12:54, "Ravindra Pesala" <[hidden email]> wrote: > >Hi, > > > >You mean Carbon do the sorting if the order by column is not first column > >and provide only limit values to spark. But the same job spark is also > >doing it just sorts the partition and gets the top values out of it. You > >can reduce the table_blocksize to get the better sort performance as spark > >try to do sorting inside memory. > > > >I can see we can do some optimizations in integration layer itself with out > >pushing down any logic to carbon like if the order by column is first > >column then we can just get limit values with out sorting any data. > > > >Regards, > >Ravindra. > > > >On 29 March 2017 at 08:58, 马云 <[hidden email]> wrote: > > > >> Hi Ravindran, > >> Thanks for your quick response. please see my answer as below > >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >> What if the order by column is not the first column? It needs to scan all > >> blocklets to get the data out of it if the order by column is not first > >> column of mdk > >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >> Answer : if step2 doesn't filter any blocklet, you are right,It needs to > >> scan all blocklets to get the data out of it if the order by column is not > >> first column of mdk > >> but it just scan all the order by column's data, for > >> others columns data, use the lazy-load strategy and it can reduce scan > >> accordingly to limit value. > >> Hence you can see the performance is much better now > >> after my optimization. Currently the carbondata order by + limit > >> performance is very bad since it scans all data. > >> in my test there are 20,000,000 data, it takes more than > >> 10s, if data is much more huge, I think it is hard for user to stand such > >> bad performance when they do order by + limit query? > >> > >> > >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >> We used to have multiple push down optimizations from spark to carbon > >> like aggregation, limit, topn etc. But later it was removed because it is > >> very hard to maintain for version to version. I feel it is better that > >> execution engine like spark can do these type of operations. > >> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >> Answer : In my opinion, I don't think "hard to maintain for version to > >> version" is a good reason to give up the order by + limit optimization. > >> I think it can create new class to extends current and try to reduce the > >> impact for the current code. Maybe can make it is easy to maintain. > >> Maybe I am wrong. > >> > >> > >> > >> > >> At 2017-03-29 02:21:58, "Ravindra Pesala" <[hidden email]> wrote: > >> > >> > >> Hi Jarck Ma, > >> > >> It is great to try optimizing Carbondata. > >> I think this solution comes up with many limitations. What if the order by > >> column is not the first column? It needs to scan all blocklets to get the > >> data out of it if the order by column is not first column of mdk. > >> > >> We used to have multiple push down optimizations from spark to carbon like > >> aggregation, limit, topn etc. But later it was removed because it is very > >> hard to maintain for version to version. I feel it is better that execution > >> engine like spark can do these type of operations. > >> > >> > >> Regards, > >> Ravindra. > >> > >> > >> > >> On Tue, Mar 28, 2017, 14:28 马云 <[hidden email]> wrote: > >> > >> > >> Hi Carbon Dev, > >> > >> Currently I have done optimization for ordering by 1 dimension. > >> > >> my local performance test as below. Please give your suggestion. > >> > >> > >> > >> > >> | data count | test sql | limit value in sql | performance(ms) | > >> | optimized code | original code | > >> | 20,000,000 | SELECT name, serialname, country, salary, id, date FROM t3 > >> ORDER BY country limit 1000 | 1000 | 677 | 10906 | > >> | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY > >> serialname limit 10000 | 10000 | 1897 | 12108 | > >> | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY > >> serialname limit 50000 | 50000 | 2814 | 14279 | > >> > >> my optimization solution for order by 1 dimension + limit as below > >> > >> mainly filter some unnecessary blocklets and leverage the dimension's > >> order stored feature to get sorted data in each partition. > >> > >> at last use the TakeOrderedAndProject to merge sorted data from partitions > >> > >> step1. change logical plan and push down the order by and limit > >> information to carbon scan > >> > >> and change sort physical plan to TakeOrderedAndProject since > >> data will be get and sorted in each partition > >> > >> step2. in each partition apply the limit number, blocklet's min_max index > >> to filter blocklet. > >> > >> it can reduce scan data if some blocklets were filtered > >> > >> for example, SELECT name, serialname, country, salary, id, date > >> FROM t3 ORDER BY serialname limit 10000 > >> > >> supposing there are 2 blocklets , each has 32000 data, serial name is > >> between serialname1 to serialname2 in the first blocklet > >> > >> and between serialname2 to serialname3 in the second blocklet. Actually > >> we only need to scan the first blocklet > >> > >> since 32000 > 100 and first blocklet's serial name <= second blocklet's > >> serial name > >> > >> > >> > >> step3. load the order by dimension data to scanResult. put all > >> scanResults to a TreeSet for sorting > >> > >> Other columns' data will be lazy-loaded in step4. > >> > >> step4. according to the limit value, use a iterator to get the topN sorted > >> data from the TreeSet. In the same time to load other columns data if > >> needed. > >> > >> in this step it tries to reduce scanning non-sort dimension > >> data. > >> > >> for example, SELECT name, serialname, country, salary, id, date > >> FROM t3 ORDER BY serialname limit 10000 > >> > >> supposing there are 3 blocklets , in the first 2 blocklets, serial name > >> is between serialname1 to serialname100 and each has 2500 serialname1 and > >> serialname2. > >> > >> In the third blocklet, serial name is between serialname2 to > >> serialnam100, but no serialname1 in it. > >> > >> load serial name data for the 3 blocklets and put all to a treeset sorting > >> by the min serialname. > >> > >> apparently use iterator to get the top 10000 sorted data, it only need to > >> care the first 2 blocklets(5000 serialname1 + 5000 serialname2). > >> > >> In others words, it loads serial name data for the 3 blocklets.But only > >> "load name, country, salary, id, date"'s data for the first 2 blocklets > >> > >> > >> > >> step5. TakeOrderedAndProject physical plan will be used to merge sorted > >> data from partitions > >> > >> > >> > >> the below items also can be optimized in future > >> > >> > >> > >> • leverage mdk keys' order feature to optimize the SQL who order by > >> prefix dimension columns of MDK > >> > >> • use the dimension order feature in blocklet lever and dimensions' > >> inverted index to optimize SQL who order by multi-dimensions > >> > >> > >> > >> > >> > >> > >> > >> > >> > >> > >> > >> Jarck Ma > >> > >> > >> > >> > >> > >> > >> > >> > >> > > > > > > > >-- > >Thanks & Regards, > >Ravi > > > > > -- Thanks & Regards, Ravi |
Re: Re:Re: Re: Optimize Order By + Limit Query
|
Administrator
|
In reply to this post by simafengyun
Hi
+1 for simafengyun's optimization, it looks good to me. I propose to do "limit" pushdown first, similar with filter pushdown. what is your opionion? @simafengyun For "order by" pushdown, let us work out an ideal solution to consider all aggregation push down cases. Ravindara's comment is reasonable, we need to consider decoupling spark and carbondata, otherwise maintenance cost might be high if do computing works at both side, because we need to keep utilizing Spark' computing capability along with its version evolution. Regards Liang
|

Re:Re: Re: Re: Optimize Order By + Limit Query
|
|
In reply to this post by ravipesala
Hi, Please see my answer. 1. It cannot work for dictionary columns. As there is no guarantee that dictionary allocation is in sorted order. Answer: As I know the dictionary allocation is in sorted order in block level, even in segment level, not in global level. But that's enough, please see the below example about how to get the correct sort result 2. It cannot work for no inverted index columns. Answer: One question, by default if user didn't configure a dimension column with no inverted index when create table. But after data loading, it has no inverted index in deed. in this case, is it still in sorted order in blocklet(or datachunk2) level? if yes, it's physical row id should equals the logical row id, of cause it is not necessary to create inverted index. Hence by default the solution should work for this kind of case. 3. It cannot work for measures. Answer: yes, you are right, can't support with measure column since it is not in sorted order Moreover as you mentioned that it can reduce IO, But I don't think we can reduce any IO since we need to read all blocklets to do merge sort. And I am not sure how we can keep all the data in memory until we do merge sort. Answer: we don't need to load all selected columns' data in memory. only need to load all the order by column' data in memory. others columns can use lazy-loading. We also can set a orderby-optimization flag, if user think they have not too much memory, can switch it to off. about reduce io, there are 2 ways. 1. sort blocklets according to the orderby dimensions' min(or max) values. then according to limit value to get the required blocklet for scan. 2. reduce the io for non order by" columns data since they I am still believe that this work is belonged to execution engine, not file format. This type of specific improvements may give good performance in some specific type of queries but these will give long term complications in maintainability.
|
Re: Re: Optimize Order By + Limit Query
|
|
This post was updated on .
In reply to this post by ravipesala
add images for my last post
1. about how to work for dictionary columns and guarantee to get a sort result Answer: As I know the dictionary allocation is in sorted order in block level, even in segment level, not in global level. But that's enough, please see the below example about how to get the correct sort result 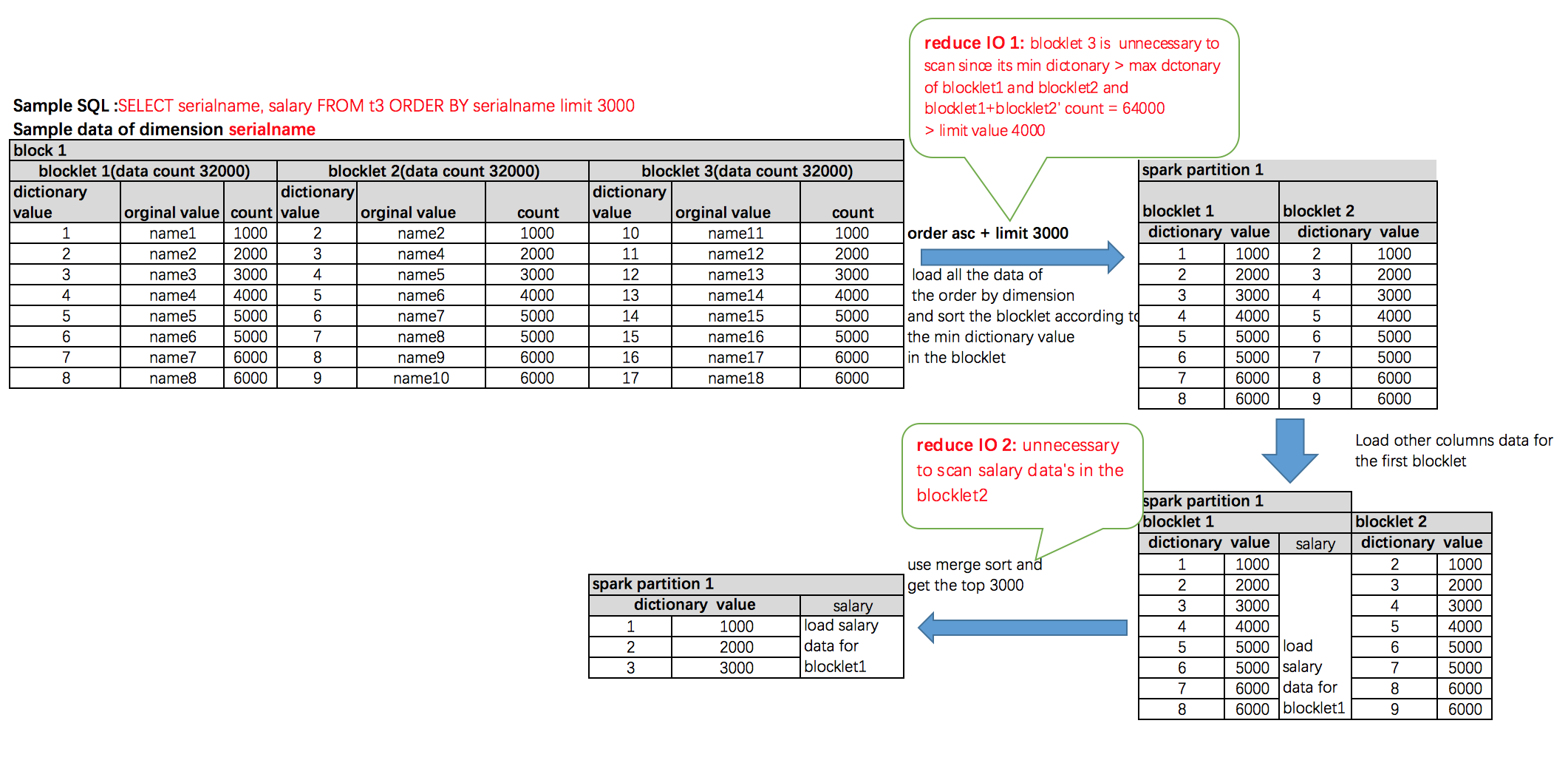 2.about how to reduce IO
|
Re: Re:Re: Re: Optimize Order By + Limit Query
|
|
In reply to this post by Liang Chen
@Liang, Yes, actually I'm currently working on the limit query
optimization. I get the limited dictionary value and convert to the filter condition in CarbonOptimizer step. It would definitely improve the query performance in some scenario. On Thu, Mar 30, 2017 at 2:07 PM, Liang Chen <[hidden email]> wrote: > Hi > > +1 for simafengyun's optimization, it looks good to me. > > I propose to do "limit" pushdown first, similar with filter pushdown. what > is your opionion? @simafengyun > > For "order by" pushdown, let us work out an ideal solution to consider all > aggregation push down cases. Ravindara's comment is reasonable, we need to > consider decoupling spark and carbondata, otherwise maintenance cost might > be high if do computing works at both side, because we need to keep > utilizing Spark' computing capability along with its version evolution. > > Regards > Liang > > > simafengyun wrote > > Hi Ravindran, > > yes, use carbon do the sorting if the order by column is not first > > column.But its sorting is very high since the dimension data in blocklet > > is stored after sorting.So in carbon can use merge sort + topN to get N > > data from each block.In addition, the biggest difference is that it can > > reduce disk IO since can use limit n to reduce required blocklets.if you > > only apply spark's top N, I don't think you can make suck below > > performance. That's impossible if don't reduce disk IO. > > > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n9834/%E6%9C%AA%E5%91%BD%E5%90%8D2.jpg> > > > > > > > > > > > > > > > > > > > > At 2017-03-30 03:12:54, "Ravindra Pesala" <[hidden email]> > > wrote: > >>Hi, > >> > >>You mean Carbon do the sorting if the order by column is not first column > >>and provide only limit values to spark. But the same job spark is also > >>doing it just sorts the partition and gets the top values out of it. You > >>can reduce the table_blocksize to get the better sort performance as > spark > >>try to do sorting inside memory. > >> > >>I can see we can do some optimizations in integration layer itself with > out > >>pushing down any logic to carbon like if the order by column is first > >>column then we can just get limit values with out sorting any data. > >> > >>Regards, > >>Ravindra. > >> > >>On 29 March 2017 at 08:58, 马云 <[hidden email]> wrote: > >> > >>> Hi Ravindran, > >>> Thanks for your quick response. please see my answer as below > >>> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >>> What if the order by column is not the first column? It needs to scan > >>> all > >>> blocklets to get the data out of it if the order by column is not first > >>> column of mdk > >>> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >>> Answer : if step2 doesn't filter any blocklet, you are right,It needs > >>> to > >>> scan all blocklets to get the data out of it if the order by column is > >>> not > >>> first column of mdk > >>> but it just scan all the order by column's data, for > >>> others columns data, use the lazy-load strategy and it can reduce > scan > >>> accordingly to limit value. > >>> Hence you can see the performance is much better now > >>> after my optimization. Currently the carbondata order by + limit > >>> performance is very bad since it scans all data. > >>> in my test there are 20,000,000 data, it takes more > than > >>> 10s, if data is much more huge, I think it is hard for user to stand > >>> such > >>> bad performance when they do order by + limit query? > >>> > >>> > >>> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >>> We used to have multiple push down optimizations from spark to carbon > >>> like aggregation, limit, topn etc. But later it was removed because it > >>> is > >>> very hard to maintain for version to version. I feel it is better that > >>> execution engine like spark can do these type of operations. > >>> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > >>> Answer : In my opinion, I don't think "hard to maintain for version to > >>> version" is a good reason to give up the order by + limit > optimization. > >>> I think it can create new class to extends current and try to reduce > the > >>> impact for the current code. Maybe can make it is easy to maintain. > >>> Maybe I am wrong. > >>> > >>> > >>> > >>> > >>> At 2017-03-29 02:21:58, "Ravindra Pesala" <[hidden email] > > > >>> wrote: > >>> > >>> > >>> Hi Jarck Ma, > >>> > >>> It is great to try optimizing Carbondata. > >>> I think this solution comes up with many limitations. What if the order > >>> by > >>> column is not the first column? It needs to scan all blocklets to get > >>> the > >>> data out of it if the order by column is not first column of mdk. > >>> > >>> We used to have multiple push down optimizations from spark to carbon > >>> like > >>> aggregation, limit, topn etc. But later it was removed because it is > >>> very > >>> hard to maintain for version to version. I feel it is better that > >>> execution > >>> engine like spark can do these type of operations. > >>> > >>> > >>> Regards, > >>> Ravindra. > >>> > >>> > >>> > >>> On Tue, Mar 28, 2017, 14:28 马云 <[hidden email]> wrote: > >>> > >>> > >>> Hi Carbon Dev, > >>> > >>> Currently I have done optimization for ordering by 1 dimension. > >>> > >>> my local performance test as below. Please give your suggestion. > >>> > >>> > >>> > >>> > >>> | data count | test sql | limit value in sql | performance(ms) | > >>> | optimized code | original code | > >>> | 20,000,000 | SELECT name, serialname, country, salary, id, date FROM > >>> t3 > >>> ORDER BY country limit 1000 | 1000 | 677 | 10906 | > >>> | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY > >>> serialname limit 10000 | 10000 | 1897 | 12108 | > >>> | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY > >>> serialname limit 50000 | 50000 | 2814 | 14279 | > >>> > >>> my optimization solution for order by 1 dimension + limit as below > >>> > >>> mainly filter some unnecessary blocklets and leverage the dimension's > >>> order stored feature to get sorted data in each partition. > >>> > >>> at last use the TakeOrderedAndProject to merge sorted data from > >>> partitions > >>> > >>> step1. change logical plan and push down the order by and limit > >>> information to carbon scan > >>> > >>> and change sort physical plan to TakeOrderedAndProject > >>> since > >>> data will be get and sorted in each partition > >>> > >>> step2. in each partition apply the limit number, blocklet's min_max > >>> index > >>> to filter blocklet. > >>> > >>> it can reduce scan data if some blocklets were filtered > >>> > >>> for example, SELECT name, serialname, country, salary, id, > >>> date > >>> FROM t3 ORDER BY serialname limit 10000 > >>> > >>> supposing there are 2 blocklets , each has 32000 data, serial name is > >>> between serialname1 to serialname2 in the first blocklet > >>> > >>> and between serialname2 to serialname3 in the second blocklet. > Actually > >>> we only need to scan the first blocklet > >>> > >>> since 32000 > 100 and first blocklet's serial name <= second blocklet's > >>> serial name > >>> > >>> > >>> > >>> step3. load the order by dimension data to scanResult. put all > >>> scanResults to a TreeSet for sorting > >>> > >>> Other columns' data will be lazy-loaded in step4. > >>> > >>> step4. according to the limit value, use a iterator to get the topN > >>> sorted > >>> data from the TreeSet. In the same time to load other columns data if > >>> needed. > >>> > >>> in this step it tries to reduce scanning non-sort dimension > >>> data. > >>> > >>> for example, SELECT name, serialname, country, salary, id, > date > >>> FROM t3 ORDER BY serialname limit 10000 > >>> > >>> supposing there are 3 blocklets , in the first 2 blocklets, serial > >>> name > >>> is between serialname1 to serialname100 and each has 2500 serialname1 > >>> and > >>> serialname2. > >>> > >>> In the third blocklet, serial name is between serialname2 to > >>> serialnam100, but no serialname1 in it. > >>> > >>> load serial name data for the 3 blocklets and put all to a treeset > >>> sorting > >>> by the min serialname. > >>> > >>> apparently use iterator to get the top 10000 sorted data, it only need > >>> to > >>> care the first 2 blocklets(5000 serialname1 + 5000 serialname2). > >>> > >>> In others words, it loads serial name data for the 3 blocklets.But > only > >>> "load name, country, salary, id, date"'s data for the first 2 blocklets > >>> > >>> > >>> > >>> step5. TakeOrderedAndProject physical plan will be used to merge sorted > >>> data from partitions > >>> > >>> > >>> > >>> the below items also can be optimized in future > >>> > >>> > >>> > >>> • leverage mdk keys' order feature to optimize the SQL who order by > >>> prefix dimension columns of MDK > >>> > >>> • use the dimension order feature in blocklet lever and dimensions' > >>> inverted index to optimize SQL who order by multi-dimensions > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >>> Jarck Ma > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >>> > >> > >> > >> > >>-- > >>Thanks & Regards, > >>Ravi > > > > > > -- > View this message in context: http://apache-carbondata- > mailing-list-archive.1130556.n5.nabble.com/Optimize-Order- > By-Limit-Query-tp9764p9846.html > Sent from the Apache CarbonData Mailing List archive mailing list archive > at Nabble.com. > |
| Free forum by Nabble | Edit this page |