Questions about dimension's sort storage feature

Questions about dimension's sort storage feature

|
This post was updated on .
Hi Carbon Dev,
I create table according to the below SQL cc.sql(""" CREATE TABLE IF NOT EXISTS t3 (ID Int, date Timestamp, country String, name String, phonetype String, serialname String, salary Int, name1 String, name2 String, name3 String, name4 String, name5 String, name6 String, name7 String, name8 String ) STORED BY 'carbondata' """) data cardinality as below. 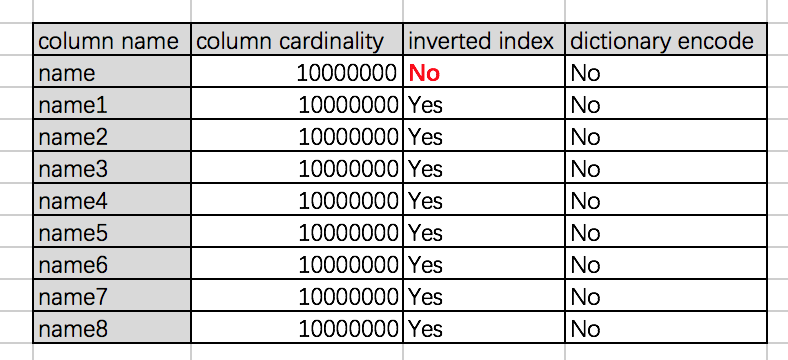 after I load data to this table, I found the dimension columns "name" and "name7" both have no dictionary encode. but column "name" has no inverted index and column "name7" has inverted index questions: 1. the dimension column name has dictionary decode, but have no inverted index, does its' data still have order in DataChunk2 blocklet? 2. is there any document to introduce these loading strategies? 3. if a dimension column has no dictionary decode and no inverted index, user also didn't specify the column with no inverted index when create table does its' data still have order in DataChunk2 blocklet? 4. as I know, by default, all dimension column data are sorted and stored in DataChunk2 blocklet except user specify the column with no inverted index, right? 5. as I know the first dimension column of mdk key is always sorted in DataChunk2 blocklet, why not set the isExplicitSorted to true? the below code is used to generate the test data.csv package test; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileOutputStream; import java.io.FileWriter; import java.util.HashMap; import java.util.Map; publicclass CreateData { public CreateData() { } publicstaticvoid main(String[] args) { FileOutputStream out = null; FileOutputStream outSTr = null; BufferedOutputStream Buff = null; FileWriter fw = null; intcount = 1000;// 写文件行数 try { outSTr = new FileOutputStream(new File("data.csv")); Buff = new BufferedOutputStream(outSTr); longbegin0 = System.currentTimeMillis(); Buff.write( "ID,date,country,name,phonetype,serialname,salary,name1,name2,name3,name4,name5,name6,name7,name8\n" .getBytes()); intidcount = 10000000; intdatecount = 30; intcountrycount = 5; // intnamecount =5000000; intphonetypecount = 10000; intserialnamecount = 50000; // intsalarycount = 200000; Map<Integer, String> countryMap = new HashMap<Integer, String>(); countryMap.put(1, "usa"); countryMap.put(2, "uk"); countryMap.put(3, "china"); countryMap.put(4, "indian"); countryMap.put(0, "canada"); StringBuilder sb = null; for (inti = idcount; i >= 0; i--) { sb = new StringBuilder(); sb.append(4000000 + i).append(",");// id sb.append("2015/8/" + (i % datecount + 1)).append(","); sb.append(countryMap.get(i % countrycount)).append(","); sb.append("name" + (1600000 - i)).append(",");// name sb.append("phone" + i % phonetypecount).append(","); sb.append("serialname" + (100000 + i % serialnamecount)).append(",");// serialname sb.append(i + 500000).append(","); sb.append("name1" + (i + 100000)).append(",");// name sb.append("name2" + (i + 200000)).append(",");// name sb.append("name3" + (i + 300000)).append(",");// name sb.append("name4" + (i + 400000)).append(",");// name sb.append("name5" + (i + 500000)).append(",");// name sb.append("name6" + (i + 600000)).append(",");// name sb.append("name7" + (i + 700000)).append(",");// name sb.append("name8" + (i + 800000)).append(",").append('\n'); Buff.write(sb.toString().getBytes()); } Buff.flush(); Buff.close(); System.out.println("sb.toString():" + sb.toString()); longend0 = System.currentTimeMillis(); System.out.println("BufferedOutputStream执行耗时:" + (end0 - begin0) + " 豪秒"); } catch (Exception e) { e.printStackTrace(); } finally { try { // fw.close(); Buff.close(); outSTr.close(); // out.close(); } catch (Exception e) { e.printStackTrace(); } } } } |
«
Return to Apache CarbonData Dev Mailing List archive
|
1 view|%1 views
| Free forum by Nabble | Edit this page |