carbondata Indenpdent reader


|
This post was updated on .
Hi,all:
Recently, I load a carbon table in hive via carbon-spark plugin. I see there is nothing in hive, and all data is stored in a folder named "storePath". scala code following: 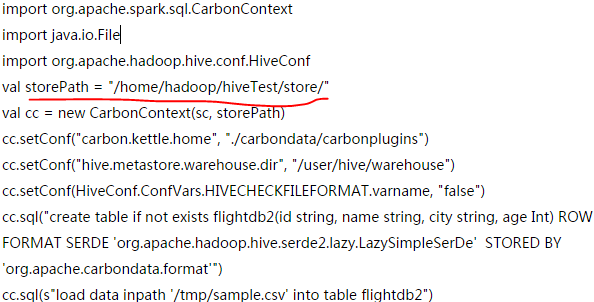 Q1: Does it mean that carbon-spark plugin just create a external table in hive and raw data can be stored anywhere? I have checked the hdfs path, there is only a table directory and nothing under the table directory. Q2: If i want to build a independent reader for carbondata table, should i read data from hive, or just parse files in the "storePath"? Q3: I check the files under "storePath", they are not sotred as hdfs format, but common files in linux. Do i get the point? Q4: I have finished brief read logic for my independent reader, all input path is local. Test1:[Carbondata-hadoop->Target->store->testdb->testtable] which contains 1K rows generated by testcase, and my code can extract data successfully. Testcase2: However, i try to parse the data generated by carbon-spark plugin which contains 100W rows, It throws exception @BlockIndexStore.fillLoadedBlocks() 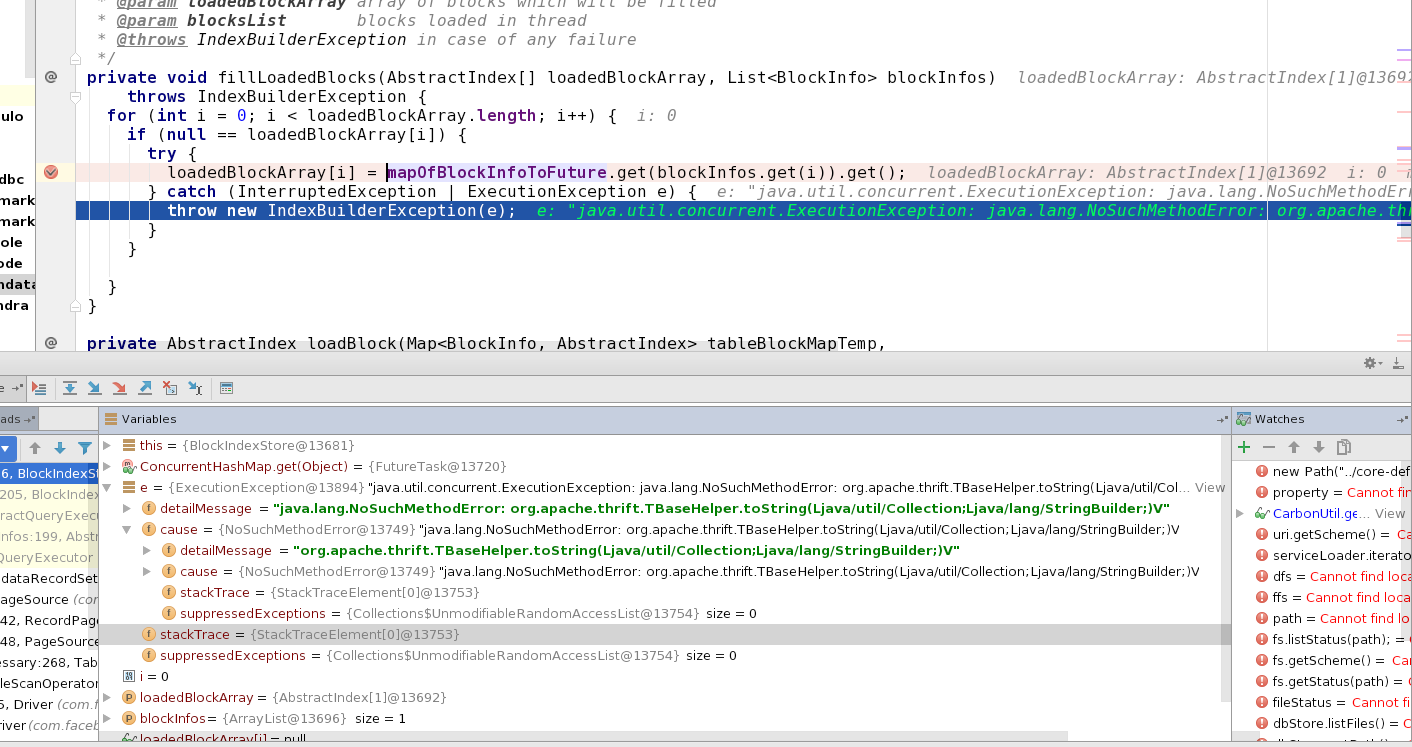 Appreciate for your regard. |
|
Administrator
|
Hi
For Q1: Carbon Data be stored under storePath , it can specify anywhere. Under "storePath", there are two folders : Fact and Metadata. As per you provided info, you specified the "storePath" is load path, this is why you can not find info from hdfs. For Q2: Please refer to examples(DatasourceExample,DirectSQLExample) For Q3: Same as Q1,please check you specified storePath. For Q4: Can not get your question exactly. you can refer to example (DirectSQLExample) , how to parse generated carbon data Regards Liang
|


|
|
Thanks for your reply. I have got the point of "storepath" and can access the data stored on hdfs.
Here is some details of Question4: I have a table "SampleA" generated by carbon-spark plugin. This table contains 3 rows, 4 columns. Now i try to extract data from this table with Query "Select * from SampleA". My Code follows, 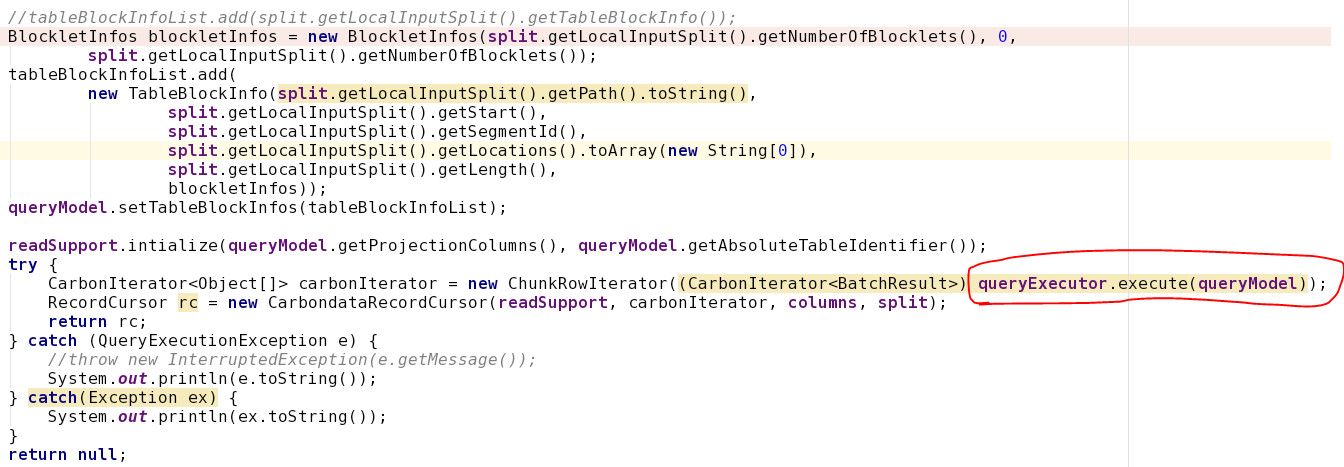 A exception was throw out from queryExecutor. so i debug into it, and locate the module BlockIndexStore. 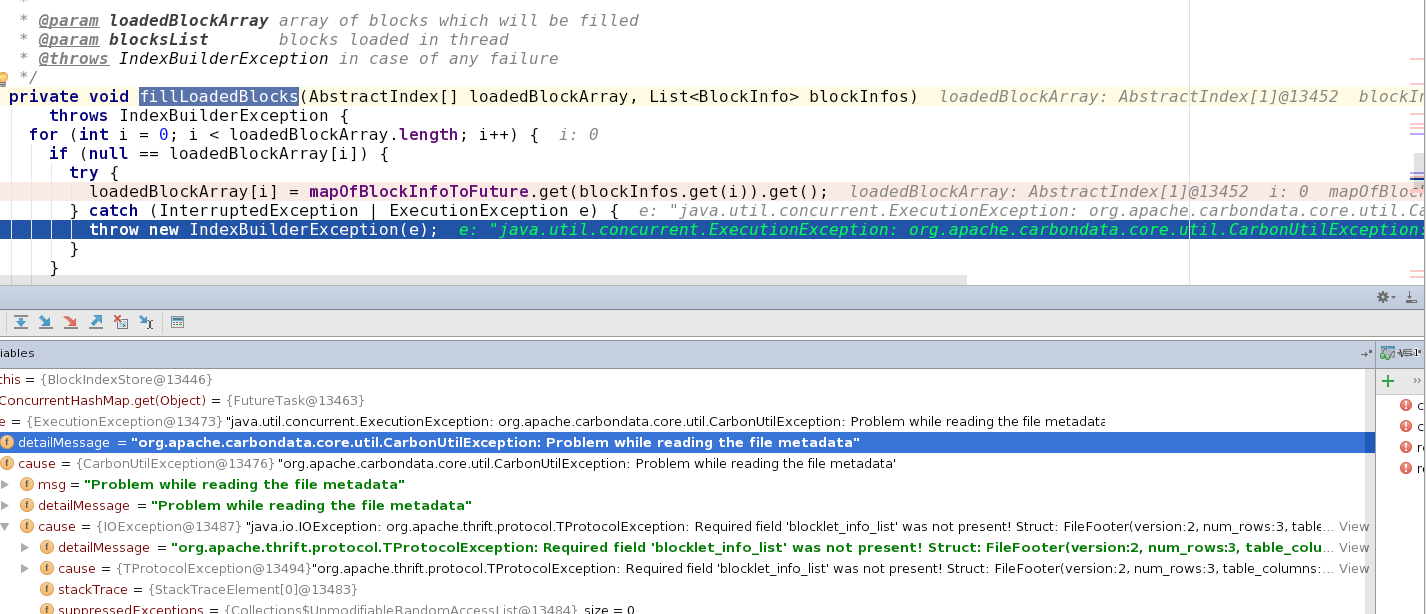 detail of exception follows, it shows that field blocklet_info_list is null: org.apache.thrift.protocol.TProtocolException: Required field 'blocklet_info_list' was not present! Struct: FileFooter( version:2, num_rows:3, table_columns:[ ColumnSchema(data_type:STRING, column_name:id, column_id:db824eef-5679-4203-9b74-ed51617a6c97, columnar:true, encoders:[DICTIONARY], dimension:true, column_group_id:-1, scale:0, precision:0, num_child:0, columnProperties:{}, invisible:false, columnReferenceId:db824eef-5679-4203-9b74-ed51617a6c97), ColumnSchema(data_type:STRING, column_name:name, column_id:b58263b0-b0be-4afc-87e4-be9a61ee6a69, columnar:true, encoders:[DICTIONARY], dimension:true, column_group_id:-1, scale:0, precision:0, num_child:0, columnProperties:{}, invisible:false, columnReferenceId:b58263b0-b0be-4afc-87e4-be9a61ee6a69), ColumnSchema(data_type:STRING, column_name:city, column_id:e52b9a1c-6dc0-490e-85df-e2c960562ed7, columnar:true, encoders:[DICTIONARY], dimension:true, column_group_id:-1, scale:0, precision:0, num_child:0, columnProperties:{}, invisible:false, columnReferenceId:e52b9a1c-6dc0-490e-85df-e2c960562ed7), ColumnSchema(data_type:INT, column_name:age, column_id:b8843c4c-f06c-40ca-922a-c3a12a4e0889, columnar:true, encoders:[], dimension:false, column_group_id:-1, scale:0, precision:0, num_child:0, columnProperties:{}, invisible:false, columnReferenceId:b8843c4c-f06c-40ca-922a-c3a12a4e0889) ], segment_info:SegmentInfo(num_cols:4, column_cardinalities:[4, 4, 3]), blocklet_index_list:[ BlockletIndex(min_max_index:BlockletMinMaxIndex(min_values:[02, 02, 02], max_values:[04, 04, 03]), b_tree_index:BlockletBTreeIndex(start_key:00 00 00 03 00 00 00 00 02 02 02, end_key:00 00 00 03 00 00 00 00 04 04 03))], blocklet_info_list:null ) However data is generated by carbon-spark plugin? So i guess is there any wrong configs for table generate process? Below is my scala progess: import org.apache.spark.sql.CarbonContext import java.io.File import org.apache.hadoop.hive.conf.HiveConf val storePath = "hdfs://10.2.26.92:9900/user/carbonstore/" val cc = new CarbonContext(sc, storePath) cc.setConf("carbon.kettle.home", "./carbondata/carbonplugins") cc.setConf("hive.metastore.warehouse.dir", "/user/hive/warehouse") cc.setConf(HiveConf.ConfVars.HIVECHECKFILEFORMAT.varname, "false") cc.sql("create table if not exists flightdb6(id string, name string, city string, age Int) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.MetadataTypedColumnsetSerDe' STORED BY 'org.apache.carbondata.format'") cc.sql(s"load data inpath '/tmp/sample.csv' into table flightdb6") |
|
Administrator
|
Hi
1.Which version are you using ? 2.Can you explain how you used carbon-spark plugin to generate carbon data ? Sorry, till now i still don't know what exact things do you want to do? you want to write some code to read carbon data? Regards Liang
|


«
Return to Apache CarbonData Dev Mailing List archive
|
1 view|%1 views
| Free forum by Nabble | Edit this page |