how to make carbon run faster


|
Hello:
i test the same data the same sql from two format ,1.carbondata 2,hive orc but carbon format run slow than orc. i use carbondata with index order like create table order hivesql:(dt is partition dir ) select count(1) as total ,status,d_id from test_orc where status !=17 and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt >= '2016-11-01' and dt <= '2016-12-26' group by status,d_id order by total desc carbonsql:(create_time is timestamp type ) select count(1) as total ,status,d_id from test_carbon where status !=17 and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and date(a.create_time)>= '2016-11-01' and date(a.create_time)<= '2016-12-26' group by status,d_id order by total desc create carbondata like CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, create_time timestamp ... ... 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop-2.6.3 like 2month ,60days 30w row per days ,600MB csv format perday $SPARK_HOME/bin/spark-shell --verbose --name "test" --master yarn-client --driver-memory 10G --executor-memory 16G --num-executors 40 --executor-cores 1 i test many case 1. gc tune ,no full gc 2. spark.sql.suffle.partition all task are in run in same time 3.carbon.conf set enable.blocklet.distribution=true i use the code to test sql run time val start = System.nanoTime() body (System.nanoTime() - start)/1000/1000 body is sqlcontext(sql).show() i find orc return back faster then carbon, to see in ui ,some times carbon ,orc are run more or less the same (i think carbon use index should be faser,or scan sequnece read is faser than idex scan),but orc is more stable ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know how to detch how time spend ) here are some pic i run (run many times ) carbon run:      orc run: 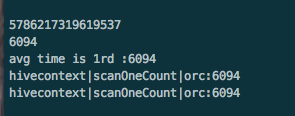  so my question is : 1. why in spark-shell,sql.show(),orc sql return faster then carbon 2. in the spark ui ,carbon should use index to skip more data,scan data some time use 4s, 2s, 0.2s ,how to make the slowest task faster? 3. like the sql ,i use the leftest index scan,so i think is should be run faster than orc test in this case ,but not ,why? 4.if the 3 question is ,exlain this ,my data is two small,so serial read is faster than index scan ? sorry for my poor english ,help,thanks! |
|
Administrator
|
Hi
Thanks for you started try Apache CarbonData project. There are may have various reasons for the test result,i assumed that you made time based partition for ORC data ,right ? 1.Can you tell that the SQL generated how many rows data? 2.You can try more SQL query, for example : select * from test_carbon where status = xx (give a specific value), the example will use the most left column to filter query(to check the indexes effectiveness) 3.Did you use how many machines(Node)? Because one executor will generate one index B+ tree , for fully utilizing index, please try to reduce the number of executor, suggest : one machine/node launch one executor(and increase the executor's memory) Regards Liang
|







|
|
1.Can you tell that the SQL generated how many rows data?
as the sql,most id are related,so is samll, 10~20 rows as rueturn result 2.You can try more SQL query, for example : select * from test_carbon where status = xx (give a specific value), the example will use the most left column to filter query(to check the indexes effectiveness) so in this case ,no partition may be on hiveorc sql, so carbon must faster 3.Did you use how many machines(Node)? Because one executor will generate one index B+ tree , for fully utilizing index, please try to reduce the number of executor, suggest : one machine/node launch one executor(and increase the executor's memory) yes ,for duebg easy and cpu conflict,i user one executor for one core for each machine but the the query run times aslo slower than orcsql thanks 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > Hi > > Thanks for you started try Apache CarbonData project. > > There are may have various reasons for the test result,i assumed that you > made time based partition for ORC data ,right ? > 1.Can you tell that the SQL generated how many rows data? > > 2.You can try more SQL query, for example : select * from test_carbon where > status = xx (give a specific value), the example will use the most left > column to filter query(to check the indexes effectiveness) > > 3.Did you use how many machines(Node)? Because one executor will generate > one index B+ tree , for fully utilizing index, please try to reduce the > number of executor, suggest : one machine/node launch one executor(and > increase the executor's memory) > > Regards > Liang > > > geda wrote > > Hello: > > i test the same data the same sql from two format ,1.carbondata 2,hive > orc > > but carbon format run slow than orc. > > i use carbondata with index order like create table order > > hivesql:(dt is partition dir ) > > select count(1) as total ,status,d_id from test_orc where status !=17 and > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt >= > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order by total > > desc > > carbonsql:(create_time is timestamp type ) > > > > select count(1) as total ,status,d_id from test_carbon where status !=17 > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > '2016-12-26' > > group by status,d_id order by total desc > > > > create carbondata like > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > create_time timestamp > > ... > > ... > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop-2.6.3 > > like > > 2month ,60days 30w row per days ,600MB csv format perday > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > yarn-client --driver-memory 10G --executor-memory 16G --num-executors > > 40 --executor-cores 1 > > i test many case > > 1. > > gc tune ,no full gc > > 2. spark.sql.suffle.partition > > all task are in run in same time > > 3.carbon.conf set > > enable.blocklet.distribution=true > > > > i use the code to test sql run time > > val start = System.nanoTime() > > body > > (System.nanoTime() - start)/1000/1000 > > > > body is sqlcontext(sql).show() > > i find orc return back faster then carbon, > > > > to see in ui ,some times carbon ,orc are run more or less the same (i > > think carbon use index should be faser,or scan sequnece read is faser > than > > idex scan),but orc is more stable > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know how to > > detch how time spend ) > > > > here are some pic i run (run many times ) > > carbon run: > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > orc run: > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > <http://apache-carbondata-mailing-list-archive.1130556. > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > so my question is : > > 1. why in spark-shell,sql.show(),orc sql return faster then carbon > > 2. in the spark ui ,carbon should use index to skip more data,scan data > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > 3. like the sql ,i use the leftest index scan,so i think is should be > run > > faster than orc test in this case ,but not ,why? > > 4.if the 3 question is ,exlain this ,my data is two small,so serial read > > is faster than index scan ? > > > > sorry for my poor english ,help,thanks! > > > > > > -- > View this message in context: http://apache-carbondata- > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > carbon-run-faster-tp5305p5322.html > Sent from the Apache CarbonData Mailing List archive mailing list archive > at Nabble.com. > |
|
Administrator
|
1.
You can add the date as filter condition also, for example : select * from test_carbon where status = xx (give a specific value) and date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > '2016-12-26'. What are your exact business cases? Partition and indexes both are good way to improve performance, suggest you increasing data set to more than 1 billion rows, and try it again. 2.Each machine only has one cpu core ? ------------------------------ yes ,for duebg easy and cpu conflict,i user one executor for one core for each machine Regards Liang 2017-01-02 12:06 GMT+08:00 北斗七 <[hidden email]>: > 1.Can you tell that the SQL generated how many rows data? > > as the sql,most id are related,so is samll, 10~20 rows as rueturn result > > 2.You can try more SQL query, for example : select * from test_carbon where > status = xx (give a specific value), the example will use the most left > column to filter query(to check the indexes effectiveness) > > so in this case ,no partition may be on hiveorc sql, so carbon must faster > 3.Did you use how many machines(Node)? Because one executor will generate > one index B+ tree , for fully utilizing index, please try to reduce the > number of executor, suggest : one machine/node launch one executor(and > increase the executor's memory) > > yes ,for duebg easy and cpu conflict,i user one executor for one core for > each machine > but the the query run times aslo slower than orcsql > > > thanks > > 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > > > Hi > > > > Thanks for you started try Apache CarbonData project. > > > > There are may have various reasons for the test result,i assumed that you > > made time based partition for ORC data ,right ? > > 1.Can you tell that the SQL generated how many rows data? > > > > 2.You can try more SQL query, for example : select * from test_carbon > where > > status = xx (give a specific value), the example will use the most left > > column to filter query(to check the indexes effectiveness) > > > > 3.Did you use how many machines(Node)? Because one executor will generate > > one index B+ tree , for fully utilizing index, please try to reduce the > > number of executor, suggest : one machine/node launch one executor(and > > increase the executor's memory) > > > > Regards > > Liang > > > > > > geda wrote > > > Hello: > > > i test the same data the same sql from two format ,1.carbondata 2,hive > > orc > > > but carbon format run slow than orc. > > > i use carbondata with index order like create table order > > > hivesql:(dt is partition dir ) > > > select count(1) as total ,status,d_id from test_orc where status !=17 > and > > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt >= > > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order by > total > > > desc > > > carbonsql:(create_time is timestamp type ) > > > > > > select count(1) as total ,status,d_id from test_carbon where status > !=17 > > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > > '2016-12-26' > > > group by status,d_id order by total desc > > > > > > create carbondata like > > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > > create_time timestamp > > > ... > > > ... > > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop-2.6.3 > > > like > > > 2month ,60days 30w row per days ,600MB csv format perday > > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > > yarn-client --driver-memory 10G --executor-memory 16G > --num-executors > > > 40 --executor-cores 1 > > > i test many case > > > 1. > > > gc tune ,no full gc > > > 2. spark.sql.suffle.partition > > > all task are in run in same time > > > 3.carbon.conf set > > > enable.blocklet.distribution=true > > > > > > i use the code to test sql run time > > > val start = System.nanoTime() > > > body > > > (System.nanoTime() - start)/1000/1000 > > > > > > body is sqlcontext(sql).show() > > > i find orc return back faster then carbon, > > > > > > to see in ui ,some times carbon ,orc are run more or less the same (i > > > think carbon use index should be faser,or scan sequnece read is faser > > than > > > idex scan),but orc is more stable > > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know how to > > > detch how time spend ) > > > > > > here are some pic i run (run many times ) > > > carbon run: > > <http://apache-carbondata-mailing-list-archive.1130556. > > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > > > orc run: > > <http://apache-carbondata-mailing-list-archive.1130556. > > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > > > > so my question is : > > > 1. why in spark-shell,sql.show(),orc sql return faster then carbon > > > 2. in the spark ui ,carbon should use index to skip more data,scan data > > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > > 3. like the sql ,i use the leftest index scan,so i think is should be > > run > > > faster than orc test in this case ,but not ,why? > > > 4.if the 3 question is ,exlain this ,my data is two small,so serial > read > > > is faster than index scan ? > > > > > > sorry for my poor english ,help,thanks! > > > > > > > > > > > > -- > > View this message in context: http://apache-carbondata- > > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > > carbon-run-faster-tp5305p5322.html > > Sent from the Apache CarbonData Mailing List archive mailing list archive > > at Nabble.com. > > > -- Regards Liang |
|
|
1.
You can add the date as filter condition also, for example : select * from test_carbon where status = xx (give a specific value) and date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > '2016-12-26'. this case test before , slow than orc What are your exact business cases? Partition and indexes both are good way to improve performance, suggest you increasing data set to more than 1 billion rows, and try it again. 2.Each machine only has one cpu core ? ------------------------------ yes ,for duebg easy and cpu conflict,i user one executor for one core for each machine each meachine has 32cores 2017-01-02 20:35 GMT+08:00 Liang Chen <[hidden email]>: > 1. > You can add the date as filter condition also, for example : select * from > test_carbon where > status = xx (give a specific value) and date(a.create_time)>= '2016-11-01' > and date(a.create_time)<= > > '2016-12-26'. > > What are your exact business cases? Partition and indexes both are good way > to improve performance, suggest you increasing data set to more than 1 > billion rows, and try it again. > > 2.Each machine only has one cpu core ? > ------------------------------ > yes ,for duebg easy and cpu conflict,i user one executor for one core for > each machine > > Regards > Liang > > > 2017-01-02 12:06 GMT+08:00 北斗七 <[hidden email]>: > > > 1.Can you tell that the SQL generated how many rows data? > > > > as the sql,most id are related,so is samll, 10~20 rows as rueturn > result > > > > 2.You can try more SQL query, for example : select * from test_carbon > where > > status = xx (give a specific value), the example will use the most left > > column to filter query(to check the indexes effectiveness) > > > > so in this case ,no partition may be on hiveorc sql, so carbon must > faster > > 3.Did you use how many machines(Node)? Because one executor will generate > > one index B+ tree , for fully utilizing index, please try to reduce the > > number of executor, suggest : one machine/node launch one executor(and > > increase the executor's memory) > > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > for > > each machine > > but the the query run times aslo slower than orcsql > > > > > > thanks > > > > 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > > > > > Hi > > > > > > Thanks for you started try Apache CarbonData project. > > > > > > There are may have various reasons for the test result,i assumed that > you > > > made time based partition for ORC data ,right ? > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > where > > > status = xx (give a specific value), the example will use the most left > > > column to filter query(to check the indexes effectiveness) > > > > > > 3.Did you use how many machines(Node)? Because one executor will > generate > > > one index B+ tree , for fully utilizing index, please try to reduce the > > > number of executor, suggest : one machine/node launch one executor(and > > > increase the executor's memory) > > > > > > Regards > > > Liang > > > > > > > > > geda wrote > > > > Hello: > > > > i test the same data the same sql from two format ,1.carbondata > 2,hive > > > orc > > > > but carbon format run slow than orc. > > > > i use carbondata with index order like create table order > > > > hivesql:(dt is partition dir ) > > > > select count(1) as total ,status,d_id from test_orc where status !=17 > > and > > > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt >= > > > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order by > > total > > > > desc > > > > carbonsql:(create_time is timestamp type ) > > > > > > > > select count(1) as total ,status,d_id from test_carbon where status > > !=17 > > > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > > > '2016-12-26' > > > > group by status,d_id order by total desc > > > > > > > > create carbondata like > > > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > > > create_time timestamp > > > > ... > > > > ... > > > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop-2.6.3 > > > > like > > > > 2month ,60days 30w row per days ,600MB csv format perday > > > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > > > yarn-client --driver-memory 10G --executor-memory 16G > > --num-executors > > > > 40 --executor-cores 1 > > > > i test many case > > > > 1. > > > > gc tune ,no full gc > > > > 2. spark.sql.suffle.partition > > > > all task are in run in same time > > > > 3.carbon.conf set > > > > enable.blocklet.distribution=true > > > > > > > > i use the code to test sql run time > > > > val start = System.nanoTime() > > > > body > > > > (System.nanoTime() - start)/1000/1000 > > > > > > > > body is sqlcontext(sql).show() > > > > i find orc return back faster then carbon, > > > > > > > > to see in ui ,some times carbon ,orc are run more or less the same (i > > > > think carbon use index should be faser,or scan sequnece read is faser > > > than > > > > idex scan),but orc is more stable > > > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know how > to > > > > detch how time spend ) > > > > > > > > here are some pic i run (run many times ) > > > > carbon run: > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > > > > > orc run: > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > > > > > > > so my question is : > > > > 1. why in spark-shell,sql.show(),orc sql return faster then carbon > > > > 2. in the spark ui ,carbon should use index to skip more data,scan > data > > > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > > > 3. like the sql ,i use the leftest index scan,so i think is should > be > > > run > > > > faster than orc test in this case ,but not ,why? > > > > 4.if the 3 question is ,exlain this ,my data is two small,so serial > > read > > > > is faster than index scan ? > > > > > > > > sorry for my poor english ,help,thanks! > > > > > > > > > > > > > > > > > > -- > > > View this message in context: http://apache-carbondata- > > > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > > > carbon-run-faster-tp5305p5322.html > > > Sent from the Apache CarbonData Mailing List archive mailing list > archive > > > at Nabble.com. > > > > > > > > > -- > Regards > Liang > |
|
|
hi, beidou
1. the amount of your data is 36GB, for 1 GB 1 block, 40 cores is enough, but i think every task may takes too long time, so i suggest to increase parallelism(for example, change --executor-cores 1 to 5) then enable.blocklet.distribution=true may make more effect. 2. try not use date function. change "date(a.create_time)>= '2016-11-01'" to "a.create_time>= '2016-11-01 00:00:00'", something like this. regards Jay ------------------ 原始邮件 ------------------ 发件人: "北斗七";<[hidden email]>; 发送时间: 2017年1月2日(星期一) 晚上9:35 收件人: "dev"<[hidden email]>; 主题: Re: how to make carbon run faster 1. You can add the date as filter condition also, for example : select * from test_carbon where status = xx (give a specific value) and date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > '2016-12-26'. this case test before , slow than orc What are your exact business cases? Partition and indexes both are good way to improve performance, suggest you increasing data set to more than 1 billion rows, and try it again. 2.Each machine only has one cpu core ? ------------------------------ yes ,for duebg easy and cpu conflict,i user one executor for one core for each machine each meachine has 32cores 2017-01-02 20:35 GMT+08:00 Liang Chen <[hidden email]>: > 1. > You can add the date as filter condition also, for example : select * from > test_carbon where > status = xx (give a specific value) and date(a.create_time)>= '2016-11-01' > and date(a.create_time)<= > > '2016-12-26'. > > What are your exact business cases? Partition and indexes both are good way > to improve performance, suggest you increasing data set to more than 1 > billion rows, and try it again. > > 2.Each machine only has one cpu core ? > ------------------------------ > yes ,for duebg easy and cpu conflict,i user one executor for one core for > each machine > > Regards > Liang > > > 2017-01-02 12:06 GMT+08:00 北斗七 <[hidden email]>: > > > 1.Can you tell that the SQL generated how many rows data? > > > > as the sql,most id are related,so is samll, 10~20 rows as rueturn > result > > > > 2.You can try more SQL query, for example : select * from test_carbon > where > > status = xx (give a specific value), the example will use the most left > > column to filter query(to check the indexes effectiveness) > > > > so in this case ,no partition may be on hiveorc sql, so carbon must > faster > > 3.Did you use how many machines(Node)? Because one executor will generate > > one index B+ tree , for fully utilizing index, please try to reduce the > > number of executor, suggest : one machine/node launch one executor(and > > increase the executor's memory) > > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > for > > each machine > > but the the query run times aslo slower than orcsql > > > > > > thanks > > > > 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > > > > > Hi > > > > > > Thanks for you started try Apache CarbonData project. > > > > > > There are may have various reasons for the test result,i assumed that > you > > > made time based partition for ORC data ,right ? > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > where > > > status = xx (give a specific value), the example will use the most left > > > column to filter query(to check the indexes effectiveness) > > > > > > 3.Did you use how many machines(Node)? Because one executor will > generate > > > one index B+ tree , for fully utilizing index, please try to reduce the > > > number of executor, suggest : one machine/node launch one executor(and > > > increase the executor's memory) > > > > > > Regards > > > Liang > > > > > > > > > geda wrote > > > > Hello: > > > > i test the same data the same sql from two format ,1.carbondata > 2,hive > > > orc > > > > but carbon format run slow than orc. > > > > i use carbondata with index order like create table order > > > > hivesql:(dt is partition dir ) > > > > select count(1) as total ,status,d_id from test_orc where status !=17 > > and > > > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt >= > > > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order by > > total > > > > desc > > > > carbonsql:(create_time is timestamp type ) > > > > > > > > select count(1) as total ,status,d_id from test_carbon where status > > !=17 > > > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > > > '2016-12-26' > > > > group by status,d_id order by total desc > > > > > > > > create carbondata like > > > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > > > create_time timestamp > > > > ... > > > > ... > > > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop-2.6.3 > > > > like > > > > 2month ,60days 30w row per days ,600MB csv format perday > > > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > > > yarn-client --driver-memory 10G --executor-memory 16G > > --num-executors > > > > 40 --executor-cores 1 > > > > i test many case > > > > 1. > > > > gc tune ,no full gc > > > > 2. spark.sql.suffle.partition > > > > all task are in run in same time > > > > 3.carbon.conf set > > > > enable.blocklet.distribution=true > > > > > > > > i use the code to test sql run time > > > > val start = System.nanoTime() > > > > body > > > > (System.nanoTime() - start)/1000/1000 > > > > > > > > body is sqlcontext(sql).show() > > > > i find orc return back faster then carbon, > > > > > > > > to see in ui ,some times carbon ,orc are run more or less the same (i > > > > think carbon use index should be faser,or scan sequnece read is faser > > > than > > > > idex scan),but orc is more stable > > > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know how > to > > > > detch how time spend ) > > > > > > > > here are some pic i run (run many times ) > > > > carbon run: > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > > > > > orc run: > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > > > > > > > so my question is : > > > > 1. why in spark-shell,sql.show(),orc sql return faster then carbon > > > > 2. in the spark ui ,carbon should use index to skip more data,scan > data > > > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > > > 3. like the sql ,i use the leftest index scan,so i think is should > be > > > run > > > > faster than orc test in this case ,but not ,why? > > > > 4.if the 3 question is ,exlain this ,my data is two small,so serial > > read > > > > is faster than index scan ? > > > > > > > > sorry for my poor english ,help,thanks! > > > > > > > > > > > > > > > > > > -- > > > View this message in context: http://apache-carbondata- > > > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > > > carbon-run-faster-tp5305p5322.html > > > Sent from the Apache CarbonData Mailing List archive mailing list > archive > > > at Nabble.com. > > > > > > > > > -- > Regards > Liang > |
|
|
is has a way ,to show carbon use index info,scan nums of lows, used time
,i use like multier index filter may be quicker,like a_id =1 and b_id=2 and c_id=3 and day='2017-01-01' ,the same to orc sql, day is used partition,but *_id not has index, but orc is faster or near equal.i thank this case ,carbon should be better ?so i wan't to know to carbon use index info or my load csv data to carbon is wrong ,so not used index ? 2017-01-03 11:08 GMT+08:00 Jay <[hidden email]>: > hi, beidou > > > 1. the amount of your data is 36GB, for 1 GB 1 block, 40 cores is > enough, > but i think every task may takes too long time, so i suggest to > increase parallelism(for example, change --executor-cores 1 to 5) > then enable.blocklet.distribution=true may make more effect. > 2. try not use date function. change "date(a.create_time)>= > '2016-11-01'" to "a.create_time>= '2016-11-01 00:00:00'", something like > this. > > > regards > Jay > > > ------------------ 原始邮件 ------------------ > 发件人: "北斗七";<[hidden email]>; > 发送时间: 2017年1月2日(星期一) 晚上9:35 > 收件人: "dev"<[hidden email]>; > > 主题: Re: how to make carbon run faster > > > > 1. > You can add the date as filter condition also, for example : select * from > test_carbon where > status = xx (give a specific value) and date(a.create_time)>= '2016-11-01' > and date(a.create_time)<= > > '2016-12-26'. > > this case test before , slow than orc > > What are your exact business cases? Partition and indexes both are good way > to improve performance, suggest you increasing data set to more than 1 > billion rows, and try it again. > > 2.Each machine only has one cpu core ? > ------------------------------ > yes ,for duebg easy and cpu conflict,i user one executor for one core for > each machine > > each meachine has 32cores > > 2017-01-02 20:35 GMT+08:00 Liang Chen <[hidden email]>: > > > 1. > > You can add the date as filter condition also, for example : select * > from > > test_carbon where > > status = xx (give a specific value) and date(a.create_time)>= > '2016-11-01' > > and date(a.create_time)<= > > > '2016-12-26'. > > > > What are your exact business cases? Partition and indexes both are good > way > > to improve performance, suggest you increasing data set to more than 1 > > billion rows, and try it again. > > > > 2.Each machine only has one cpu core ? > > ------------------------------ > > yes ,for duebg easy and cpu conflict,i user one executor for one core > for > > each machine > > > > Regards > > Liang > > > > > > 2017-01-02 12:06 GMT+08:00 北斗七 <[hidden email]>: > > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > as the sql,most id are related,so is samll, 10~20 rows as rueturn > > result > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > where > > > status = xx (give a specific value), the example will use the most left > > > column to filter query(to check the indexes effectiveness) > > > > > > so in this case ,no partition may be on hiveorc sql, so carbon must > > faster > > > 3.Did you use how many machines(Node)? Because one executor will > generate > > > one index B+ tree , for fully utilizing index, please try to reduce the > > > number of executor, suggest : one machine/node launch one executor(and > > > increase the executor's memory) > > > > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > > for > > > each machine > > > but the the query run times aslo slower than orcsql > > > > > > > > > thanks > > > > > > 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > > > > > > > Hi > > > > > > > > Thanks for you started try Apache CarbonData project. > > > > > > > > There are may have various reasons for the test result,i assumed that > > you > > > > made time based partition for ORC data ,right ? > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > > where > > > > status = xx (give a specific value), the example will use the most > left > > > > column to filter query(to check the indexes effectiveness) > > > > > > > > 3.Did you use how many machines(Node)? Because one executor will > > generate > > > > one index B+ tree , for fully utilizing index, please try to reduce > the > > > > number of executor, suggest : one machine/node launch one > executor(and > > > > increase the executor's memory) > > > > > > > > Regards > > > > Liang > > > > > > > > > > > > geda wrote > > > > > Hello: > > > > > i test the same data the same sql from two format ,1.carbondata > > 2,hive > > > > orc > > > > > but carbon format run slow than orc. > > > > > i use carbondata with index order like create table order > > > > > hivesql:(dt is partition dir ) > > > > > select count(1) as total ,status,d_id from test_orc where status > !=17 > > > and > > > > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt > >= > > > > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order by > > > total > > > > > desc > > > > > carbonsql:(create_time is timestamp type ) > > > > > > > > > > select count(1) as total ,status,d_id from test_carbon where status > > > !=17 > > > > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > > > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > > > > '2016-12-26' > > > > > group by status,d_id order by total desc > > > > > > > > > > create carbondata like > > > > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > > > > create_time timestamp > > > > > ... > > > > > ... > > > > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > > > > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop- > 2.6.3 > > > > > like > > > > > 2month ,60days 30w row per days ,600MB csv format perday > > > > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > > > > yarn-client --driver-memory 10G --executor-memory 16G > > > --num-executors > > > > > 40 --executor-cores 1 > > > > > i test many case > > > > > 1. > > > > > gc tune ,no full gc > > > > > 2. spark.sql.suffle.partition > > > > > all task are in run in same time > > > > > 3.carbon.conf set > > > > > enable.blocklet.distribution=true > > > > > > > > > > i use the code to test sql run time > > > > > val start = System.nanoTime() > > > > > body > > > > > (System.nanoTime() - start)/1000/1000 > > > > > > > > > > body is sqlcontext(sql).show() > > > > > i find orc return back faster then carbon, > > > > > > > > > > to see in ui ,some times carbon ,orc are run more or less the same > (i > > > > > think carbon use index should be faser,or scan sequnece read is > faser > > > > than > > > > > idex scan),but orc is more stable > > > > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know > how > > to > > > > > detch how time spend ) > > > > > > > > > > here are some pic i run (run many times ) > > > > > carbon run: > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > > > > > > > orc run: > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > > > > > > > > > > so my question is : > > > > > 1. why in spark-shell,sql.show(),orc sql return faster then carbon > > > > > 2. in the spark ui ,carbon should use index to skip more data,scan > > data > > > > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > > > > 3. like the sql ,i use the leftest index scan,so i think is should > > be > > > > run > > > > > faster than orc test in this case ,but not ,why? > > > > > 4.if the 3 question is ,exlain this ,my data is two small,so serial > > > read > > > > > is faster than index scan ? > > > > > > > > > > sorry for my poor english ,help,thanks! > > > > > > > > > > > > > > > > > > > > > > > > -- > > > > View this message in context: http://apache-carbondata- > > > > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > > > > carbon-run-faster-tp5305p5322.html > > > > Sent from the Apache CarbonData Mailing List archive mailing list > > archive > > > > at Nabble.com. > > > > > > > > > > > > > > > -- > > Regards > > Liang > > > |
|
|
in carbon.properties, set enable.query.statistics=true,
then the query detail can be get, and then u can check. regards Jay ------------------ 原始邮件 ------------------ 发件人: "北斗七";<[hidden email]>; 发送时间: 2017年1月3日(星期二) 中午12:15 收件人: "dev"<[hidden email]>; 主题: Re: how to make carbon run faster is has a way ,to show carbon use index info,scan nums of lows, used time ,i use like multier index filter may be quicker,like a_id =1 and b_id=2 and c_id=3 and day='2017-01-01' ,the same to orc sql, day is used partition,but *_id not has index, but orc is faster or near equal.i thank this case ,carbon should be better ?so i wan't to know to carbon use index info or my load csv data to carbon is wrong ,so not used index ? 2017-01-03 11:08 GMT+08:00 Jay <[hidden email]>: > hi, beidou > > > 1. the amount of your data is 36GB, for 1 GB 1 block, 40 cores is > enough, > but i think every task may takes too long time, so i suggest to > increase parallelism(for example, change --executor-cores 1 to 5) > then enable.blocklet.distribution=true may make more effect. > 2. try not use date function. change "date(a.create_time)>= > '2016-11-01'" to "a.create_time>= '2016-11-01 00:00:00'", something like > this. > > > regards > Jay > > > ------------------ 原始邮件 ------------------ > 发件人: "北斗七";<[hidden email]>; > 发送时间: 2017年1月2日(星期一) 晚上9:35 > 收件人: "dev"<[hidden email]>; > > 主题: Re: how to make carbon run faster > > > > 1. > You can add the date as filter condition also, for example : select * from > test_carbon where > status = xx (give a specific value) and date(a.create_time)>= '2016-11-01' > and date(a.create_time)<= > > '2016-12-26'. > > this case test before , slow than orc > > What are your exact business cases? Partition and indexes both are good way > to improve performance, suggest you increasing data set to more than 1 > billion rows, and try it again. > > 2.Each machine only has one cpu core ? > ------------------------------ > yes ,for duebg easy and cpu conflict,i user one executor for one core for > each machine > > each meachine has 32cores > > 2017-01-02 20:35 GMT+08:00 Liang Chen <[hidden email]>: > > > 1. > > You can add the date as filter condition also, for example : select * > from > > test_carbon where > > status = xx (give a specific value) and date(a.create_time)>= > '2016-11-01' > > and date(a.create_time)<= > > > '2016-12-26'. > > > > What are your exact business cases? Partition and indexes both are good > way > > to improve performance, suggest you increasing data set to more than 1 > > billion rows, and try it again. > > > > 2.Each machine only has one cpu core ? > > ------------------------------ > > yes ,for duebg easy and cpu conflict,i user one executor for one core > for > > each machine > > > > Regards > > Liang > > > > > > 2017-01-02 12:06 GMT+08:00 北斗七 <[hidden email]>: > > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > as the sql,most id are related,so is samll, 10~20 rows as rueturn > > result > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > where > > > status = xx (give a specific value), the example will use the most left > > > column to filter query(to check the indexes effectiveness) > > > > > > so in this case ,no partition may be on hiveorc sql, so carbon must > > faster > > > 3.Did you use how many machines(Node)? Because one executor will > generate > > > one index B+ tree , for fully utilizing index, please try to reduce the > > > number of executor, suggest : one machine/node launch one executor(and > > > increase the executor's memory) > > > > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > > for > > > each machine > > > but the the query run times aslo slower than orcsql > > > > > > > > > thanks > > > > > > 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > > > > > > > Hi > > > > > > > > Thanks for you started try Apache CarbonData project. > > > > > > > > There are may have various reasons for the test result,i assumed that > > you > > > > made time based partition for ORC data ,right ? > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > > where > > > > status = xx (give a specific value), the example will use the most > left > > > > column to filter query(to check the indexes effectiveness) > > > > > > > > 3.Did you use how many machines(Node)? Because one executor will > > generate > > > > one index B+ tree , for fully utilizing index, please try to reduce > the > > > > number of executor, suggest : one machine/node launch one > executor(and > > > > increase the executor's memory) > > > > > > > > Regards > > > > Liang > > > > > > > > > > > > geda wrote > > > > > Hello: > > > > > i test the same data the same sql from two format ,1.carbondata > > 2,hive > > > > orc > > > > > but carbon format run slow than orc. > > > > > i use carbondata with index order like create table order > > > > > hivesql:(dt is partition dir ) > > > > > select count(1) as total ,status,d_id from test_orc where status > !=17 > > > and > > > > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt > >= > > > > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order by > > > total > > > > > desc > > > > > carbonsql:(create_time is timestamp type ) > > > > > > > > > > select count(1) as total ,status,d_id from test_carbon where status > > > !=17 > > > > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > > > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > > > > '2016-12-26' > > > > > group by status,d_id order by total desc > > > > > > > > > > create carbondata like > > > > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > > > > create_time timestamp > > > > > ... > > > > > ... > > > > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > > > > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop- > 2.6.3 > > > > > like > > > > > 2month ,60days 30w row per days ,600MB csv format perday > > > > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > > > > yarn-client --driver-memory 10G --executor-memory 16G > > > --num-executors > > > > > 40 --executor-cores 1 > > > > > i test many case > > > > > 1. > > > > > gc tune ,no full gc > > > > > 2. spark.sql.suffle.partition > > > > > all task are in run in same time > > > > > 3.carbon.conf set > > > > > enable.blocklet.distribution=true > > > > > > > > > > i use the code to test sql run time > > > > > val start = System.nanoTime() > > > > > body > > > > > (System.nanoTime() - start)/1000/1000 > > > > > > > > > > body is sqlcontext(sql).show() > > > > > i find orc return back faster then carbon, > > > > > > > > > > to see in ui ,some times carbon ,orc are run more or less the same > (i > > > > > think carbon use index should be faser,or scan sequnece read is > faser > > > > than > > > > > idex scan),but orc is more stable > > > > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know > how > > to > > > > > detch how time spend ) > > > > > > > > > > here are some pic i run (run many times ) > > > > > carbon run: > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > > > > > > > orc run: > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > > > > > > > > > > so my question is : > > > > > 1. why in spark-shell,sql.show(),orc sql return faster then carbon > > > > > 2. in the spark ui ,carbon should use index to skip more data,scan > > data > > > > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > > > > 3. like the sql ,i use the leftest index scan,so i think is should > > be > > > > run > > > > > faster than orc test in this case ,but not ,why? > > > > > 4.if the 3 question is ,exlain this ,my data is two small,so serial > > > read > > > > > is faster than index scan ? > > > > > > > > > > sorry for my poor english ,help,thanks! > > > > > > > > > > > > > > > > > > > > > > > > -- > > > > View this message in context: http://apache-carbondata- > > > > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > > > > carbon-run-faster-tp5305p5322.html > > > > Sent from the Apache CarbonData Mailing List archive mailing list > > archive > > > > at Nabble.com. > > > > > > > > > > > > > > > -- > > Regards > > Liang > > > |
|
|
17/01/03 15:20:17 STATISTIC QueryStatisticsRecorderImpl: Time taken for
Carbon Optimizer to optimize: 2 17/01/03 15:20:23 STATISTIC DriverQueryStatisticsRecorderImpl: Print query statistic for query id: 6047652460423237 +--------+--------------------+---------------------+------------------------+ | Module| Operation Step| Total Query Cost| Query Cost| +--------+--------------------+---------------------+------------------------+ | Driver| Load blocks driver| | 5518 | | +--------------------+ +------------------------+ | Part| Block allocation| 5536 | 17 | | +--------------------+ +------------------------+ | |Block identification| | 1 | +--------+--------------------+---------------------+------------------------+ i find the the slowest task stderr +------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ | task_id|load_blocks_time|load_dictionary_time|scan_blocks_time|total_executor_time|scan_blocks_num|total_blockletvalid_scan_blocklet|result_size| +------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ |6047652460423237_7| 0 | 4 | 48 | 1650 | 9 | 9 | 3 | +------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ then how to debug total_executor_time use 1650 . this is the more faster +-------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ | task_id|load_blocks_time|load_dictionary_time|scan_blocks_time|total_executor_time|scan_blocks_num|total_blockletvalid_scan_blocklet|result_size| +-------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ |6047652460423237_19| 0 | 4 | 12 | 107 | 9 | 9 | 2 | +-------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ 1650 vs 107 ? scan_blocks_num is the same 9. 2017-01-03 14:35 GMT+08:00 Jay <[hidden email]>: > in carbon.properties, set enable.query.statistics=true, > then the query detail can be get, and then u can check. > > > regards > Jay > > > > > ------------------ 原始邮件 ------------------ > 发件人: "北斗七";<[hidden email]>; > 发送时间: 2017年1月3日(星期二) 中午12:15 > 收件人: "dev"<[hidden email]>; > > 主题: Re: how to make carbon run faster > > > > is has a way ,to show carbon use index info,scan nums of lows, used time > ,i use like multier index filter may be quicker,like a_id =1 and b_id=2 > and c_id=3 and day='2017-01-01' ,the same to orc sql, day is used > partition,but *_id not has index, but orc is faster or near equal.i thank > this case ,carbon should be better ?so i wan't to know to carbon use index > info or my load csv data to carbon is wrong ,so not used index ? > > 2017-01-03 11:08 GMT+08:00 Jay <[hidden email]>: > > > hi, beidou > > > > > > 1. the amount of your data is 36GB, for 1 GB 1 block, 40 cores is > > enough, > > but i think every task may takes too long time, so i suggest to > > increase parallelism(for example, change --executor-cores 1 to 5) > > then enable.blocklet.distribution=true may make more effect. > > 2. try not use date function. change "date(a.create_time)>= > > '2016-11-01'" to "a.create_time>= '2016-11-01 00:00:00'", something like > > this. > > > > > > regards > > Jay > > > > > > ------------------ 原始邮件 ------------------ > > 发件人: "北斗七";<[hidden email]>; > > 发送时间: 2017年1月2日(星期一) 晚上9:35 > > 收件人: "dev"<[hidden email]>; > > > > 主题: Re: how to make carbon run faster > > > > > > > > 1. > > You can add the date as filter condition also, for example : select * > from > > test_carbon where > > status = xx (give a specific value) and date(a.create_time)>= > '2016-11-01' > > and date(a.create_time)<= > > > '2016-12-26'. > > > > this case test before , slow than orc > > > > What are your exact business cases? Partition and indexes both are good > way > > to improve performance, suggest you increasing data set to more than 1 > > billion rows, and try it again. > > > > 2.Each machine only has one cpu core ? > > ------------------------------ > > yes ,for duebg easy and cpu conflict,i user one executor for one core > for > > each machine > > > > each meachine has 32cores > > > > 2017-01-02 20:35 GMT+08:00 Liang Chen <[hidden email]>: > > > > > 1. > > > You can add the date as filter condition also, for example : select * > > from > > > test_carbon where > > > status = xx (give a specific value) and date(a.create_time)>= > > '2016-11-01' > > > and date(a.create_time)<= > > > > '2016-12-26'. > > > > > > What are your exact business cases? Partition and indexes both are good > > way > > > to improve performance, suggest you increasing data set to more than 1 > > > billion rows, and try it again. > > > > > > 2.Each machine only has one cpu core ? > > > ------------------------------ > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > > for > > > each machine > > > > > > Regards > > > Liang > > > > > > > > > 2017-01-02 12:06 GMT+08:00 北斗七 <[hidden email]>: > > > > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > > > as the sql,most id are related,so is samll, 10~20 rows as rueturn > > > result > > > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > > where > > > > status = xx (give a specific value), the example will use the most > left > > > > column to filter query(to check the indexes effectiveness) > > > > > > > > so in this case ,no partition may be on hiveorc sql, so carbon must > > > faster > > > > 3.Did you use how many machines(Node)? Because one executor will > > generate > > > > one index B+ tree , for fully utilizing index, please try to reduce > the > > > > number of executor, suggest : one machine/node launch one > executor(and > > > > increase the executor's memory) > > > > > > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > > > for > > > > each machine > > > > but the the query run times aslo slower than orcsql > > > > > > > > > > > > thanks > > > > > > > > 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > > > > > > > > > Hi > > > > > > > > > > Thanks for you started try Apache CarbonData project. > > > > > > > > > > There are may have various reasons for the test result,i assumed > that > > > you > > > > > made time based partition for ORC data ,right ? > > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > > > > > 2.You can try more SQL query, for example : select * from > test_carbon > > > > where > > > > > status = xx (give a specific value), the example will use the most > > left > > > > > column to filter query(to check the indexes effectiveness) > > > > > > > > > > 3.Did you use how many machines(Node)? Because one executor will > > > generate > > > > > one index B+ tree , for fully utilizing index, please try to reduce > > the > > > > > number of executor, suggest : one machine/node launch one > > executor(and > > > > > increase the executor's memory) > > > > > > > > > > Regards > > > > > Liang > > > > > > > > > > > > > > > geda wrote > > > > > > Hello: > > > > > > i test the same data the same sql from two format ,1.carbondata > > > 2,hive > > > > > orc > > > > > > but carbon format run slow than orc. > > > > > > i use carbondata with index order like create table order > > > > > > hivesql:(dt is partition dir ) > > > > > > select count(1) as total ,status,d_id from test_orc where status > > !=17 > > > > and > > > > > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt > > >= > > > > > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order > by > > > > total > > > > > > desc > > > > > > carbonsql:(create_time is timestamp type ) > > > > > > > > > > > > select count(1) as total ,status,d_id from test_carbon where > status > > > > !=17 > > > > > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > > > > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > > > > > '2016-12-26' > > > > > > group by status,d_id order by total desc > > > > > > > > > > > > create carbondata like > > > > > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > > > > > create_time timestamp > > > > > > ... > > > > > > ... > > > > > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > > > > > > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop- > > 2.6.3 > > > > > > like > > > > > > 2month ,60days 30w row per days ,600MB csv format perday > > > > > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > > > > > yarn-client --driver-memory 10G --executor-memory 16G > > > > --num-executors > > > > > > 40 --executor-cores 1 > > > > > > i test many case > > > > > > 1. > > > > > > gc tune ,no full gc > > > > > > 2. spark.sql.suffle.partition > > > > > > all task are in run in same time > > > > > > 3.carbon.conf set > > > > > > enable.blocklet.distribution=true > > > > > > > > > > > > i use the code to test sql run time > > > > > > val start = System.nanoTime() > > > > > > body > > > > > > (System.nanoTime() - start)/1000/1000 > > > > > > > > > > > > body is sqlcontext(sql).show() > > > > > > i find orc return back faster then carbon, > > > > > > > > > > > > to see in ui ,some times carbon ,orc are run more or less the > same > > (i > > > > > > think carbon use index should be faser,or scan sequnece read is > > faser > > > > > than > > > > > > idex scan),but orc is more stable > > > > > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know > > how > > > to > > > > > > detch how time spend ) > > > > > > > > > > > > here are some pic i run (run many times ) > > > > > > carbon run: > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > > > > > > > > > orc run: > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > > > > > > > > > > > > > so my question is : > > > > > > 1. why in spark-shell,sql.show(),orc sql return faster then > carbon > > > > > > 2. in the spark ui ,carbon should use index to skip more > data,scan > > > data > > > > > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > > > > > 3. like the sql ,i use the leftest index scan,so i think is > should > > > be > > > > > run > > > > > > faster than orc test in this case ,but not ,why? > > > > > > 4.if the 3 question is ,exlain this ,my data is two small,so > serial > > > > read > > > > > > is faster than index scan ? > > > > > > > > > > > > sorry for my poor english ,help,thanks! > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > -- > > > > > View this message in context: http://apache-carbondata- > > > > > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > > > > > carbon-run-faster-tp5305p5322.html > > > > > Sent from the Apache CarbonData Mailing List archive mailing list > > > archive > > > > > at Nabble.com. > > > > > > > > > > > > > > > > > > > > > -- > > > Regards > > > Liang > > > > > > |
|
|
checked.
one big possible reason is too many small file, compacted firstly ,then we can try regards Jay ------------------ 原始邮件 ------------------ 发件人: "北斗七";<[hidden email]>; 发送时间: 2017年1月3日(星期二) 下午3:29 收件人: "dev"<[hidden email]>; 主题: Re: how to make carbon run faster 17/01/03 15:20:17 STATISTIC QueryStatisticsRecorderImpl: Time taken for Carbon Optimizer to optimize: 2 17/01/03 15:20:23 STATISTIC DriverQueryStatisticsRecorderImpl: Print query statistic for query id: 6047652460423237 +--------+--------------------+---------------------+------------------------+ | Module| Operation Step| Total Query Cost| Query Cost| +--------+--------------------+---------------------+------------------------+ | Driver| Load blocks driver| | 5518 | | +--------------------+ +------------------------+ | Part| Block allocation| 5536 | 17 | | +--------------------+ +------------------------+ | |Block identification| | 1 | +--------+--------------------+---------------------+------------------------+ i find the the slowest task stderr +------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ | task_id|load_blocks_time|load_dictionary_time|scan_blocks_time|total_executor_time|scan_blocks_num|total_blockletvalid_scan_blocklet|result_size| +------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ |6047652460423237_7| 0 | 4 | 48 | 1650 | 9 | 9 | 3 | +------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ then how to debug total_executor_time use 1650 . this is the more faster +-------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ | task_id|load_blocks_time|load_dictionary_time|scan_blocks_time|total_executor_time|scan_blocks_num|total_blockletvalid_scan_blocklet|result_size| +-------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ |6047652460423237_19| 0 | 4 | 12 | 107 | 9 | 9 | 2 | +-------------------+----------------+--------------------+----------------+-------------------+---------------+---------------------------------+-----------+ 1650 vs 107 ? scan_blocks_num is the same 9. 2017-01-03 14:35 GMT+08:00 Jay <[hidden email]>: > in carbon.properties, set enable.query.statistics=true, > then the query detail can be get, and then u can check. > > > regards > Jay > > > > > ------------------ 原始邮件 ------------------ > 发件人: "北斗七";<[hidden email]>; > 发送时间: 2017年1月3日(星期二) 中午12:15 > 收件人: "dev"<[hidden email]>; > > 主题: Re: how to make carbon run faster > > > > is has a way ,to show carbon use index info,scan nums of lows, used time > ,i use like multier index filter may be quicker,like a_id =1 and b_id=2 > and c_id=3 and day='2017-01-01' ,the same to orc sql, day is used > partition,but *_id not has index, but orc is faster or near equal.i thank > this case ,carbon should be better ?so i wan't to know to carbon use index > info or my load csv data to carbon is wrong ,so not used index ? > > 2017-01-03 11:08 GMT+08:00 Jay <[hidden email]>: > > > hi, beidou > > > > > > 1. the amount of your data is 36GB, for 1 GB 1 block, 40 cores is > > enough, > > but i think every task may takes too long time, so i suggest to > > increase parallelism(for example, change --executor-cores 1 to 5) > > then enable.blocklet.distribution=true may make more effect. > > 2. try not use date function. change "date(a.create_time)>= > > '2016-11-01'" to "a.create_time>= '2016-11-01 00:00:00'", something like > > this. > > > > > > regards > > Jay > > > > > > ------------------ 原始邮件 ------------------ > > 发件人: "北斗七";<[hidden email]>; > > 发送时间: 2017年1月2日(星期一) 晚上9:35 > > 收件人: "dev"<[hidden email]>; > > > > 主题: Re: how to make carbon run faster > > > > > > > > 1. > > You can add the date as filter condition also, for example : select * > from > > test_carbon where > > status = xx (give a specific value) and date(a.create_time)>= > '2016-11-01' > > and date(a.create_time)<= > > > '2016-12-26'. > > > > this case test before , slow than orc > > > > What are your exact business cases? Partition and indexes both are good > way > > to improve performance, suggest you increasing data set to more than 1 > > billion rows, and try it again. > > > > 2.Each machine only has one cpu core ? > > ------------------------------ > > yes ,for duebg easy and cpu conflict,i user one executor for one core > for > > each machine > > > > each meachine has 32cores > > > > 2017-01-02 20:35 GMT+08:00 Liang Chen <[hidden email]>: > > > > > 1. > > > You can add the date as filter condition also, for example : select * > > from > > > test_carbon where > > > status = xx (give a specific value) and date(a.create_time)>= > > '2016-11-01' > > > and date(a.create_time)<= > > > > '2016-12-26'. > > > > > > What are your exact business cases? Partition and indexes both are good > > way > > > to improve performance, suggest you increasing data set to more than 1 > > > billion rows, and try it again. > > > > > > 2.Each machine only has one cpu core ? > > > ------------------------------ > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > > for > > > each machine > > > > > > Regards > > > Liang > > > > > > > > > 2017-01-02 12:06 GMT+08:00 北斗七 <[hidden email]>: > > > > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > > > as the sql,most id are related,so is samll, 10~20 rows as rueturn > > > result > > > > > > > > 2.You can try more SQL query, for example : select * from test_carbon > > > where > > > > status = xx (give a specific value), the example will use the most > left > > > > column to filter query(to check the indexes effectiveness) > > > > > > > > so in this case ,no partition may be on hiveorc sql, so carbon must > > > faster > > > > 3.Did you use how many machines(Node)? Because one executor will > > generate > > > > one index B+ tree , for fully utilizing index, please try to reduce > the > > > > number of executor, suggest : one machine/node launch one > executor(and > > > > increase the executor's memory) > > > > > > > > yes ,for duebg easy and cpu conflict,i user one executor for one core > > > for > > > > each machine > > > > but the the query run times aslo slower than orcsql > > > > > > > > > > > > thanks > > > > > > > > 2017-01-02 11:24 GMT+08:00 Liang Chen <[hidden email]>: > > > > > > > > > Hi > > > > > > > > > > Thanks for you started try Apache CarbonData project. > > > > > > > > > > There are may have various reasons for the test result,i assumed > that > > > you > > > > > made time based partition for ORC data ,right ? > > > > > 1.Can you tell that the SQL generated how many rows data? > > > > > > > > > > 2.You can try more SQL query, for example : select * from > test_carbon > > > > where > > > > > status = xx (give a specific value), the example will use the most > > left > > > > > column to filter query(to check the indexes effectiveness) > > > > > > > > > > 3.Did you use how many machines(Node)? Because one executor will > > > generate > > > > > one index B+ tree , for fully utilizing index, please try to reduce > > the > > > > > number of executor, suggest : one machine/node launch one > > executor(and > > > > > increase the executor's memory) > > > > > > > > > > Regards > > > > > Liang > > > > > > > > > > > > > > > geda wrote > > > > > > Hello: > > > > > > i test the same data the same sql from two format ,1.carbondata > > > 2,hive > > > > > orc > > > > > > but carbon format run slow than orc. > > > > > > i use carbondata with index order like create table order > > > > > > hivesql:(dt is partition dir ) > > > > > > select count(1) as total ,status,d_id from test_orc where status > > !=17 > > > > and > > > > > > v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and dt > > >= > > > > > > '2016-11-01' and dt <= '2016-12-26' group by status,d_id order > by > > > > total > > > > > > desc > > > > > > carbonsql:(create_time is timestamp type ) > > > > > > > > > > > > select count(1) as total ,status,d_id from test_carbon where > status > > > > !=17 > > > > > > and v_id in ( 91532,91533,91534,91535,91536,91537,10001 ) and > > > > > > date(a.create_time)>= '2016-11-01' and date(a.create_time)<= > > > > > '2016-12-26' > > > > > > group by status,d_id order by total desc > > > > > > > > > > > > create carbondata like > > > > > > CREATE TABLE test_carbon ( status int, v_id bigint, d_id bigint, > > > > > > create_time timestamp > > > > > > ... > > > > > > ... > > > > > > 'DICTIONARY_INCLUDE'='status,d_id,v_id,create_time') > > > > > > > > > > > > run with spark-shell,on 40 node ,spark1.6.1,carbon0.20,hadoop- > > 2.6.3 > > > > > > like > > > > > > 2month ,60days 30w row per days ,600MB csv format perday > > > > > > $SPARK_HOME/bin/spark-shell --verbose --name "test" --master > > > > > > yarn-client --driver-memory 10G --executor-memory 16G > > > > --num-executors > > > > > > 40 --executor-cores 1 > > > > > > i test many case > > > > > > 1. > > > > > > gc tune ,no full gc > > > > > > 2. spark.sql.suffle.partition > > > > > > all task are in run in same time > > > > > > 3.carbon.conf set > > > > > > enable.blocklet.distribution=true > > > > > > > > > > > > i use the code to test sql run time > > > > > > val start = System.nanoTime() > > > > > > body > > > > > > (System.nanoTime() - start)/1000/1000 > > > > > > > > > > > > body is sqlcontext(sql).show() > > > > > > i find orc return back faster then carbon, > > > > > > > > > > > > to see in ui ,some times carbon ,orc are run more or less the > same > > (i > > > > > > think carbon use index should be faser,or scan sequnece read is > > faser > > > > > than > > > > > > idex scan),but orc is more stable > > > > > > ui show spend 5s,but return time orc 8s,carbon 12s.(i don't know > > how > > > to > > > > > > detch how time spend ) > > > > > > > > > > > > here are some pic i run (run many times ) > > > > > > carbon run: > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run1.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-run2.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run1.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-job-total-run2.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/carbon-slowest-run2.png> > > > > > > > > > > > > orc run: > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/hiveconext-slowest-job-total-run1.png> > > > > > > > > > > > <http://apache-carbondata-mailing-list-archive.1130556. > > > > > n5.nabble.com/file/n5305/hiveconext-slowest-total-run1.png> > > > > > > > > > > > > > > > > > > so my question is : > > > > > > 1. why in spark-shell,sql.show(),orc sql return faster then > carbon > > > > > > 2. in the spark ui ,carbon should use index to skip more > data,scan > > > data > > > > > > some time use 4s, 2s, 0.2s ,how to make the slowest task faster? > > > > > > 3. like the sql ,i use the leftest index scan,so i think is > should > > > be > > > > > run > > > > > > faster than orc test in this case ,but not ,why? > > > > > > 4.if the 3 question is ,exlain this ,my data is two small,so > serial > > > > read > > > > > > is faster than index scan ? > > > > > > > > > > > > sorry for my poor english ,help,thanks! > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > -- > > > > > View this message in context: http://apache-carbondata- > > > > > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > > > > > carbon-run-faster-tp5305p5322.html > > > > > Sent from the Apache CarbonData Mailing List archive mailing list > > > archive > > > > > at Nabble.com. > > > > > > > > > > > > > > > > > > > > > -- > > > Regards > > > Liang > > > > > > |
Re: 回复: how to make carbon run faster
|
|
This post was updated on .
HI,
Total memory of cluster is 16G*40 = 640GB, total size of data file is 600/1024GB*60 = 35GB, so I suggest to load all data files(60 days) once. BTW, if loading small data file(total size) for each data loading, it will generate small carbon files. You can add "carbon.enable.auto.load.merge=true" to carbon.properties file to enable compaction feature. When loading data again, will trigger compaction.
Best Regards
David Cai |
|
|
thanks,alter compact not work,i change to set auto.load
error is the same INFO 04-01 16:47:20,676 - main compaction need status is true AUDIT 04-01 16:47:20,676 - [datanode07.bi][qixing][Thread-1]Compaction request received for table test INFO 04-01 16:47:20,679 - main Acquired the compaction lock. INFO 04-01 16:47:20,693 - main loads identified for merge is 0 INFO 04-01 16:47:20,693 - main loads identified for merge is 1 INFO 04-01 16:47:20,693 - main loads identified for merge is 2 INFO 04-01 16:47:20,693 - main loads identified for merge is 3 INFO 04-01 16:47:20,693 - main loads identified for merge is 4 INFO 04-01 16:47:20,693 - main loads identified for merge is 5 INFO 04-01 16:47:20,706 - pool-24-thread-1 spark.executor.instances property is set to =8 INFO 04-01 16:47:20,806 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 INFO 04-01 16:47:20,812 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 INFO 04-01 16:47:20,821 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 INFO 04-01 16:47:20,827 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 INFO 04-01 16:47:20,834 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 INFO 04-01 16:47:20,840 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 INFO 04-01 16:47:20,846 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 INFO 04-01 16:47:20,852 - pool-24-thread-1 ************************Total Number Rows In BTREE: 1 ERROR 04-01 16:47:20,859 - main Exception in compaction thread java.io.IOException: java.lang.NullPointerException 2017-01-04 12:28 GMT+08:00 QiangCai <[hidden email]>: > HI, > Total memory of cluster is 16G*40 = 640GB, total size of data file is > 600/1024GB*60 = 35GB, so I suggest to load all data files(60 days) once. > > BTW, if loading small data file(total size) for each data loading, it will > generate small carbon files. > You can add "carbon.enable.auto.load.merge=true" to carbon.properties file > to enable compaction feature. > > > > -- > View this message in context: http://apache-carbondata- > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > carbon-run-faster-tp5305p5427.html > Sent from the Apache CarbonData Mailing List archive mailing list archive > at Nabble.com. > |
Re: 回复: how to make carbon run faster
|
Administrator
|
Hi
First: i suggest you reload data again, one time to load all 35G data , to check the query effectiveness again. Second: After you finish the above E2E test, you would understand the whole process of Carbon. then i suggest you start to read source code and some technical documents for further understanding carbon detail. BTW, what david provided solution, need to reload data. Regards Liang |
|
|
BTW, what david provided solution, need to reload data.
Yes,reload data to a new table,trigger compact ,aslo error 2017-01-04 18:00 GMT+08:00 Liang Chen <[hidden email]>: > Hi > > First: i suggest you reload data again, one time to load all 35G data , to > check the query effectiveness again. > Second: After you finish the above E2E test, you would understand the whole > process of Carbon. then i suggest you start to read source code and some > technical documents for further understanding carbon detail. > > BTW, what david provided solution, need to reload data. > > Regards > Liang > > > > -- > View this message in context: http://apache-carbondata- > mailing-list-archive.1130556.n5.nabble.com/how-to-make- > carbon-run-faster-tp5305p5468.html > Sent from the Apache CarbonData Mailing List archive mailing list archive > at Nabble.com. > |
Re: 回复: how to make carbon run faster
|
Administrator
|
OK,can you provide the detailed steps of reproduce the error, and raise one apache JIRA.
Regards Liang |
«
Return to Apache CarbonData Dev Mailing List archive
|
1 view|%1 views
| Free forum by Nabble | Edit this page |