Hi,all:
Recently, i meet a strange problem.
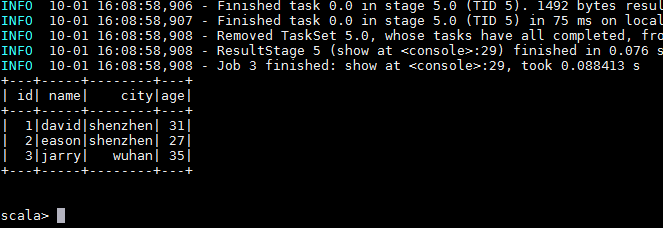
i create a table via plugin carbondata-spark and stored it on local path with table name "flightdb2". I can read it with spark, all seems to be ok.
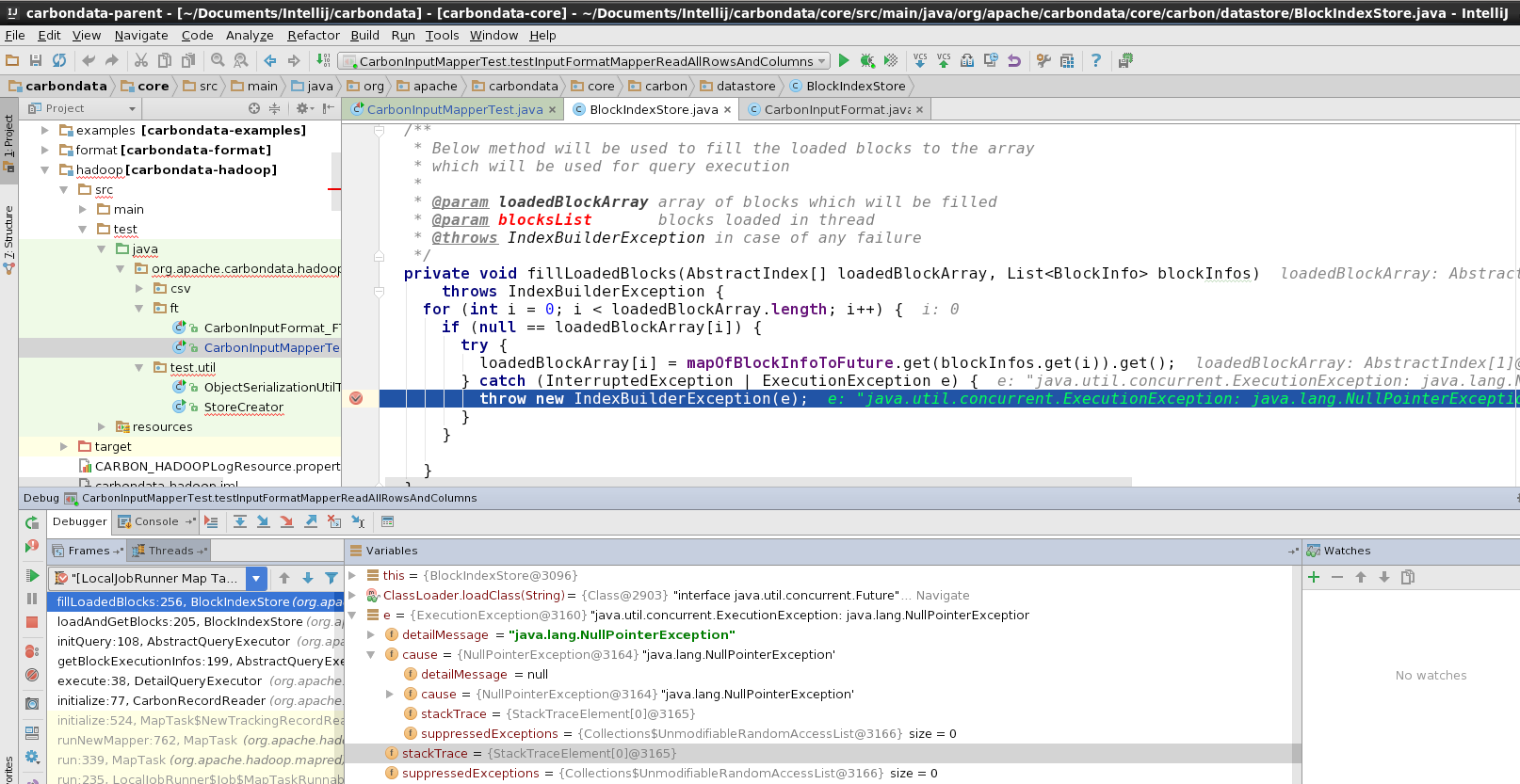
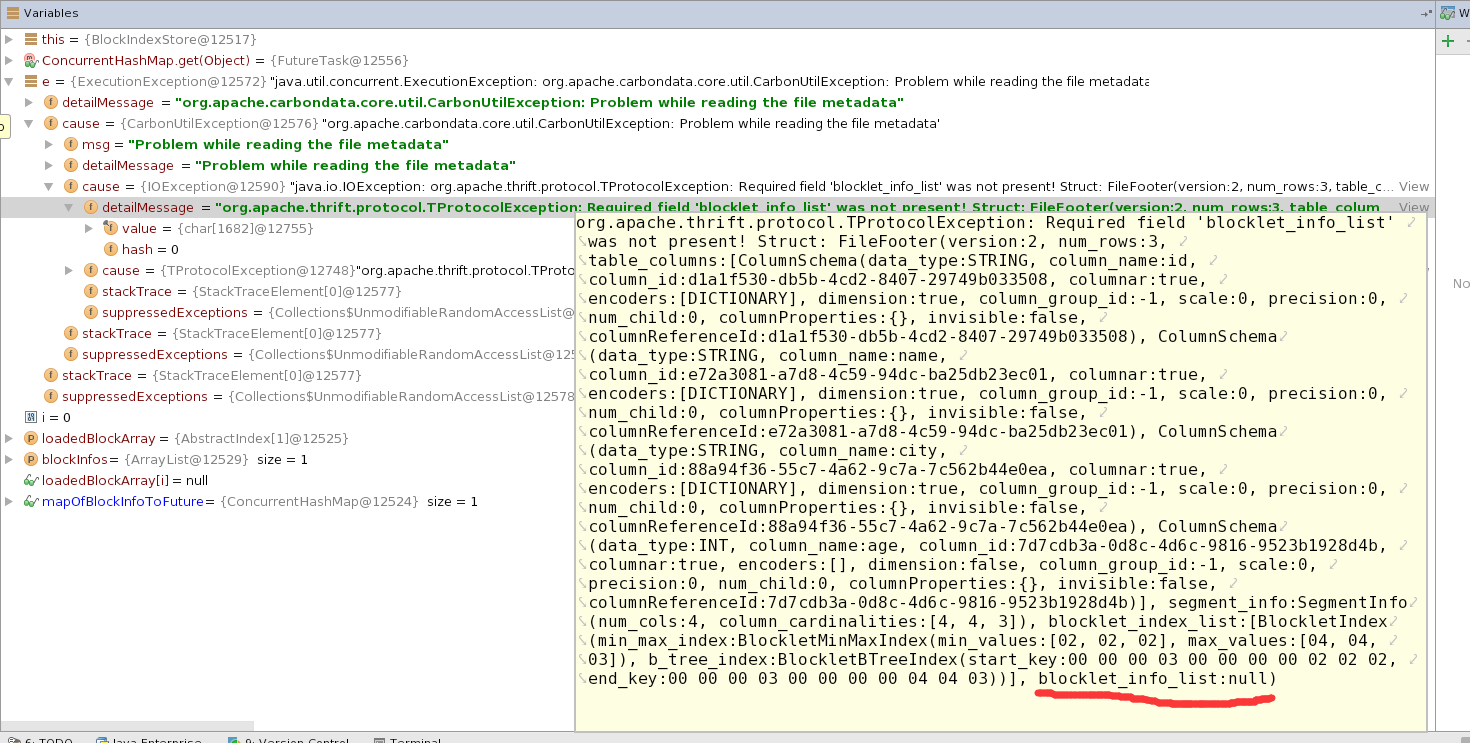
Then i try to use a testCase to read table "flightdb2". The testCase is CarbonInputMapperTest and it is in Module carbondata-hadoop. However this testCase will fail with error "NullPointerException".
Case CarbonInputMapperTest.testInputFormatMapperReadAllRowsAndColumns will success when read table "testtable" which created by StoreCreator.
All code is cloned from github and is clean, so I want to know the difference between table "flightdb2" and "testtable"?