carbondata test join question
Posted by geda on
URL: http://apache-carbondata-dev-mailing-list-archive.168.s1.nabble.com/carbondata-test-join-question-tp4440.html
hello
i want to test orc ,carbon , which is faster
test on yarn with 8 executors, each executor 4G,each 2 core
spark1.6 ,carbon2.0
sql : join 3 table
A :300W row,5GB
B:13W row,30MB
C:7W row,10MB
like this:
select b.id ,b.d_name ,a.v_no,count(*) o_count from a left join b on a.d_id=b.id left join c on c.v_no=a.v_no where date(a.create_time)>= '2016-07-01' and date(a.create_time)<= '2016-09-02' group by b.id , b.d_name, a.v_no having o_count> 30 order by b.id desc
use context
cc.sql($SQL).show() : carbondata :run 5times avg time :7.3s
hiveContext.sql($SQL).show() : ORC : run 5times avg time:5.3s
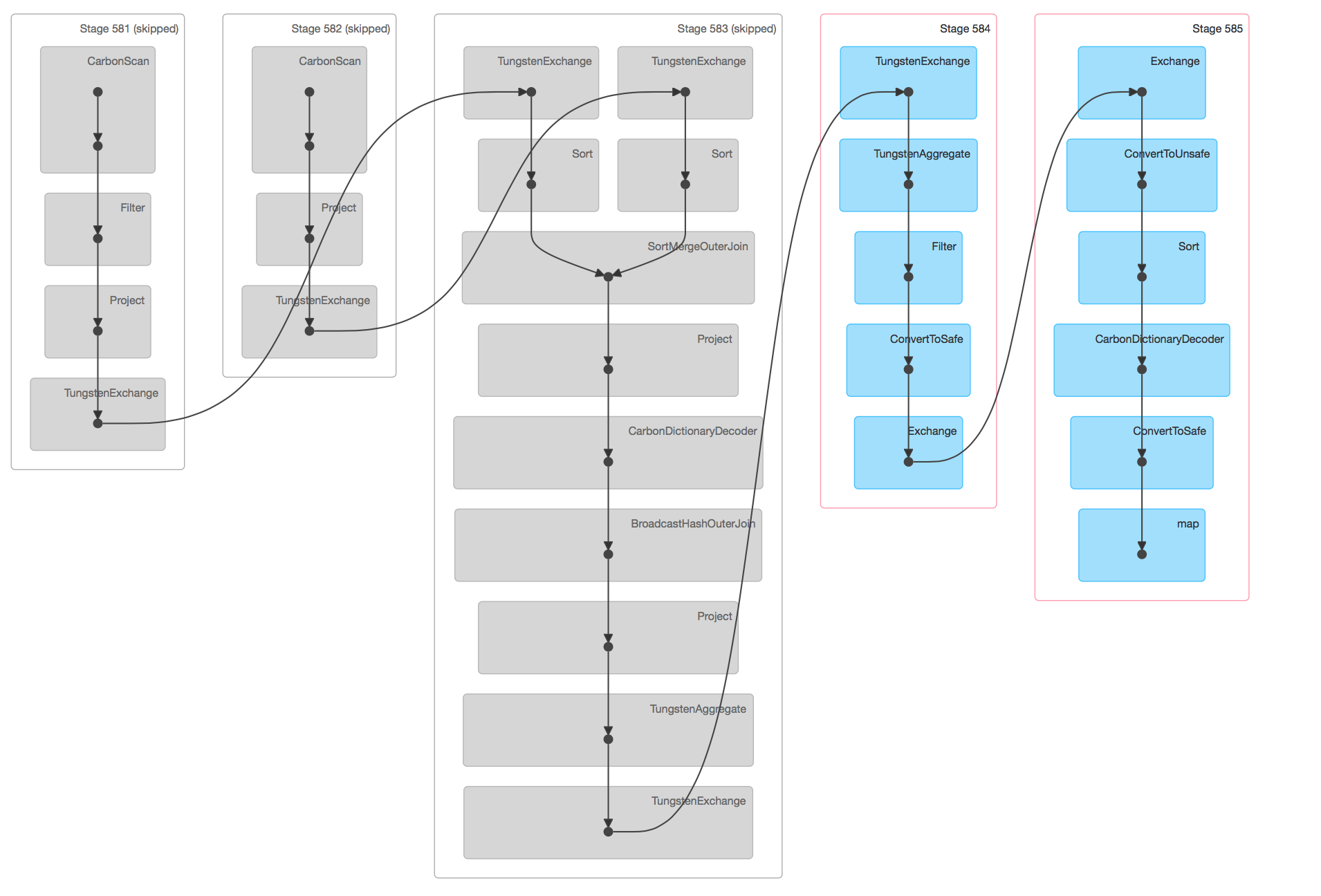
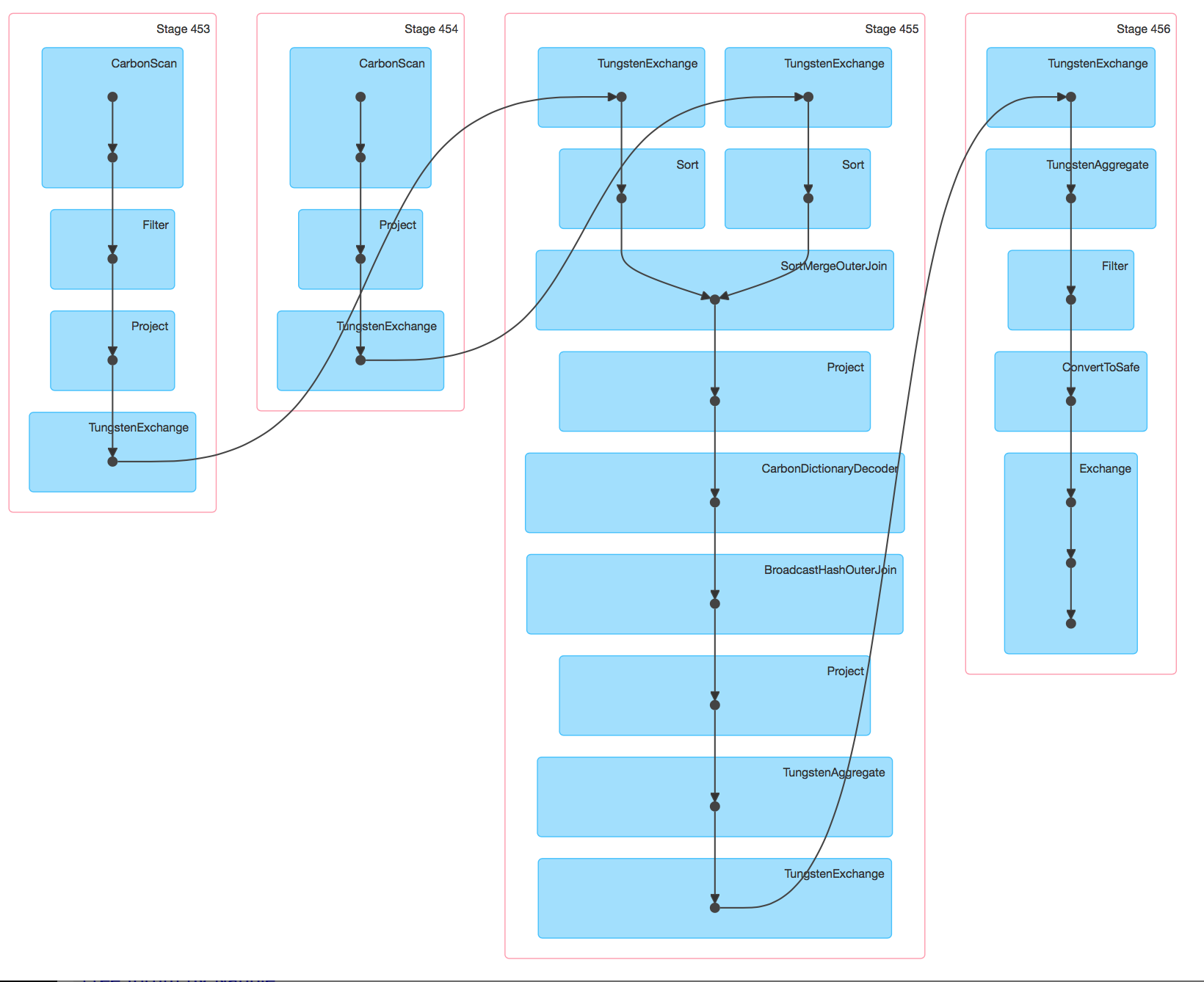
i find from DAG ,carbon has a more job ,do carbon decode ,finish this job cause 2-3s spend
if strip this job ,carbon and orc use time more or less the same
i want to know how to strip the last stage or how to tune sql like this .Thanks

URL: http://apache-carbondata-dev-mailing-list-archive.168.s1.nabble.com/carbondata-test-join-question-tp4440.html
hello
i want to test orc ,carbon , which is faster
test on yarn with 8 executors, each executor 4G,each 2 core
spark1.6 ,carbon2.0
sql : join 3 table
A :300W row,5GB
B:13W row,30MB
C:7W row,10MB
like this:
select b.id ,b.d_name ,a.v_no,count(*) o_count from a left join b on a.d_id=b.id left join c on c.v_no=a.v_no where date(a.create_time)>= '2016-07-01' and date(a.create_time)<= '2016-09-02' group by b.id , b.d_name, a.v_no having o_count> 30 order by b.id desc
use context
cc.sql($SQL).show() : carbondata :run 5times avg time :7.3s
hiveContext.sql($SQL).show() : ORC : run 5times avg time:5.3s
i find from DAG ,carbon has a more job ,do carbon decode ,finish this job cause 2-3s spend
if strip this job ,carbon and orc use time more or less the same
i want to know how to strip the last stage or how to tune sql like this .Thanks
| Free forum by Nabble | Edit this page |