Optimize Order By + Limit Query
URL: http://apache-carbondata-dev-mailing-list-archive.168.s1.nabble.com/Optimize-Order-By-Limit-Query-tp9764.html
Hi Carbon Dev,
Currently I have done optimization for ordering by 1 dimension.
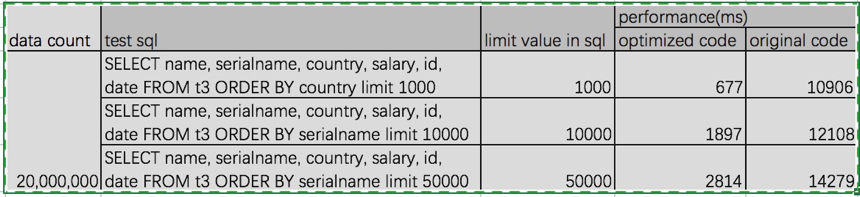
my local performance test as below. Please give your suggestion.
| data count | test sql | limit value in sql | performance(ms) | |
| optimized code | original code | |||
| 20,000,000 | SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY country limit 1000 | 1000 | 677 | 10906 |
| SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000 | 10000 | 1897 | 12108 | |
| SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 50000 | 50000 | 2814 | 14279 | |
my optimization solution for order by 1 dimension + limit as below
mainly filter some unnecessary blocklets and leverage the dimension's order stored feature to get sorted data in each partition.
at last use the TakeOrderedAndProject to merge sorted data from partitions
step1. change logical plan and push down the order by and limit information to carbon scan
and change sort physical plan to TakeOrderedAndProject since data will be get and sorted in each partition
step2. in each partition apply the limit number, blocklet's min_max index to filter blocklet.
it can reduce scan data if some blocklets were filtered
for example, SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000
supposing there are 2 blocklets , each has 32000 data, serial name is between serialname1 to serialname2 in the first blocklet
and between serialname2 to serialname3 in the second blocklet. Actually we only need to scan the first blocklet
since 32000 > 100 and first blocklet's serial name <= second blocklet's serial name
step3. load the order by dimension data to scanResult. put all scanResults to a TreeSet for sorting
Other columns' data will be lazy-loaded in step4.
step4. according to the limit value, use a iterator to get the topN sorted data from the TreeSet. In the same time to load other columns data if needed.
in this step it tries to reduce scanning non-sort dimension data.
for example, SELECT name, serialname, country, salary, id, date FROM t3 ORDER BY serialname limit 10000
supposing there are 3 blocklets , in the first 2 blocklets, serial name is between serialname1 to serialname100 and each has 2500 serialname1 and serialname2.
In the third blocklet, serial name is between serialname2 to serialnam100, but no serialname1 in it.
load serial name data for the 3 blocklets and put all to a treeset sorting by the min serialname.
apparently use iterator to get the top 10000 sorted data, it only need to care the first 2 blocklets(5000 serialname1 + 5000 serialname2).
In others words, it loads serial name data for the 3 blocklets.But only "load name, country, salary, id, date"'s data for the first 2 blocklets
step5. TakeOrderedAndProject physical plan will be used to merge sorted data from partitions
the below items also can be optimized in future
• leverage mdk keys' order feature to optimize the SQL who order by prefix dimension columns of MDK
• use the dimension order feature in blocklet lever and dimensions' inverted index to optimize SQL who order by multi-dimensions
Jarck Ma
| Free forum by Nabble | Edit this page |