can't apply mappartitions to dataframe generated from carboncontext


|
hi: appendix are the full error message I try to modify dataframe row in non-sql way and get Task not serializable,my test procedure like follows: 1.val df=cc.sql(select * from t1) 2.def function1 (iterator: Iterator[Row]):Iterator[Row]={ var list=scala.collection.mutable.ListBuffer[Row]() while (iterator.hasNext) { var r=iterator.next if(r.getAs[String]("col1").toString.equalsIgnoreCase(r.getAs[String]("col2").toString)) list+=r} list.iterator } 3.df.mapPartitions(r=>function1 (r)) I also apply function1 to dataframe generated from sqlContext work fine, so i believe carboncontext is refering some outer variables that are not serializable.
孙而焓【FFCS研究院】
|
|
|
Hi, Mic sun
Can you ping your error message directly ? It seems I can't get access to your appendix. Thanks in advance. Regards. Chenerlu. |
|
|
In reply to this post by 孙而焓
org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304) at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294) at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122) at org.apache.spark.SparkContext.clean(SparkContext.scala:2054) at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1.apply(RDD.scala:926) at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1.apply(RDD.scala:925) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111) at org.apache.spark.rdd.RDD.withScope(RDD.scala:323) at org.apache.spark.rdd.RDD.foreachPartition(RDD.scala:925) at org.apache.spark.sql.DataFrame$$anonfun$foreachPartition$1.apply$mcV$sp(DataFrame.scala:1445) at org.apache.spark.sql.DataFrame$$anonfun$foreachPartition$1.apply(DataFrame.scala:1445) at org.apache.spark.sql.DataFrame$$anonfun$foreachPartition$1.apply(DataFrame.scala:1445) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:56) at org.apache.spark.sql.DataFrame.withNewExecutionId(DataFrame.scala:2087) at org.apache.spark.sql.DataFrame.foreachPartition(DataFrame.scala:1444) at $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:66) at $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:72) at $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:74) at $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:76) at $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:78) at $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:80) at $iwC$$iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:82) at $iwC$$iwC$$iwC$$iwC$$iwC.<init>(<console>:84) at $iwC$$iwC$$iwC$$iwC.<init>(<console>:86) at $iwC$$iwC$$iwC.<init>(<console>:88) at $iwC$$iwC.<init>(<console>:90) at $iwC.<init>(<console>:92) at <init>(<console>:94) at .<init>(<console>:98) at .<clinit>(<console>) at .<init>(<console>:7) at .<clinit>(<console>) at $print(<console>) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:1065) at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1346) at org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:840) at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:871) at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:819) at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$pasteCommand(SparkILoop.scala:825) at org.apache.spark.repl.SparkILoop$$anonfun$standardCommands$8.apply(SparkILoop.scala:345) at org.apache.spark.repl.SparkILoop$$anonfun$standardCommands$8.apply(SparkILoop.scala:345) at scala.tools.nsc.interpreter.LoopCommands$LoopCommand$$anonfun$nullary$1.apply(LoopCommands.scala:65) at scala.tools.nsc.interpreter.LoopCommands$LoopCommand$$anonfun$nullary$1.apply(LoopCommands.scala:65) at scala.tools.nsc.interpreter.LoopCommands$NullaryCmd.apply(LoopCommands.scala:76) at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:809) at org.apache.spark.repl.SparkILoop.processLine$1(SparkILoop.scala:657) at org.apache.spark.repl.SparkILoop.innerLoop$1(SparkILoop.scala:665) at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$loop(SparkILoop.scala:670) at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$1.apply$mcZ$sp(SparkILoop.scala:997) at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$1.apply(SparkILoop.scala:945) at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$1.apply(SparkILoop.scala:945) at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:135) at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$process(SparkILoop.scala:945) at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:1059) at org.apache.spark.repl.Main$.main(Main.scala:31) at org.apache.spark.repl.Main.main(Main.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:745) at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181) at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) Caused by: java.io.NotSerializableException: org.apache.spark.sql.hive.client.ClientWrapper Serialization stack: - object not serializable (class: org.apache.spark.sql.hive.client.ClientWrapper, value: org.apache.spark.sql.hive.client.ClientWrapper@7ed95080) - field (class: org.apache.spark.sql.CarbonContext, name: hiveClientInterface, type: interface org.apache.spark.sql.hive.client.ClientInterface) - object (class org.apache.spark.sql.CarbonContext, org.apache.spark.sql.CarbonContext@2db12c5b) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: cc, type: class org.apache.spark.sql.CarbonContext) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@2bb24bfd) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@615ac367) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@26f53217) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@1f616814) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC@617c8b14) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC@6c8b9ad6) - field (class: $iwC$$iwC$$iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC@211b80de) - field (class: $iwC$$iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC, $iwC$$iwC$$iwC@7406a29c) - field (class: $iwC$$iwC, name: $iw, type: class $iwC$$iwC$$iwC) - object (class $iwC$$iwC, $iwC$$iwC@4ae0a804) - field (class: $iwC, name: $iw, type: class $iwC$$iwC) - object (class $iwC, $iwC@41d93c6f) - field (class: $line20.$read, name: $iw, type: class $iwC) - object (class $line20.$read, $line20.$read@19c682ee) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $VAL1283, type: class $line20.$read) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@481ebe9d) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $outer, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@7ab8ddf6) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $outer, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@665947eb) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, name: $outer, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC, $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC@91b6c3c) - field (class: $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$anonfun$3, name: $outer, type: class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC) - object (class $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$anonfun$3, <function1>) at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40) at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47) at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101) at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301) ... 69 more
孙而焓【FFCS研究院】
|
|
|
In reply to this post by 孙而焓
Hi,
I check in my IntelliJ, but can not reproduce your issue, please check whether it is environment problem ? Test steps as follows, correct me if I made a mistake 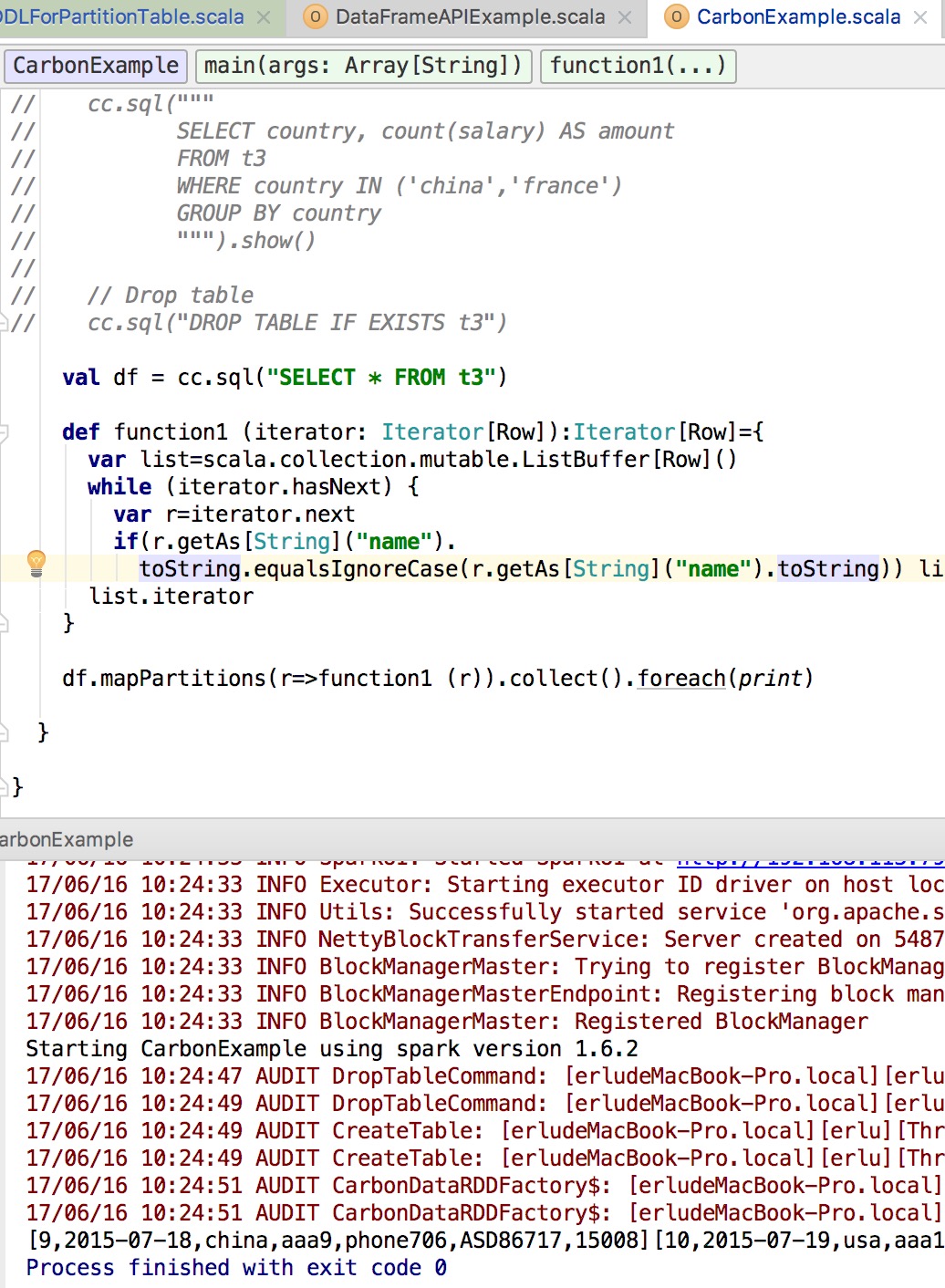 Regards. Chenerlu. |
答复: can't apply mappartitions to dataframe generated from carboncontext
|
|
Hi all,
When view or debug carbondata code,shoud I choose windows + IntelliJ develop enviorment,the Hadoop is install in a linux machine.Or I must use linxu+ IntelliJ,and Hadoop is install in the linux . -----邮件原件----- 发件人: Erlu Chen [mailto:[hidden email]] 发送时间: 2017年6月16日 10:39 收件人: [hidden email] 主题: Re: can't apply mappartitions to dataframe generated from carboncontext Hi, I check in my IntelliJ, but can not reproduce your issue, please check whether it is environment problem ? Test steps as follows, correct me if I made a mistake <http://apache-carbondata-dev-mailing-list-archive.1130556.n5.nabble.com/file/n15277/WechatIMG6.jpeg> Regards. Chenerlu. -- View this message in context: http://apache-carbondata-dev-mailing-list-archive.1130556.n5.nabble.com/can-t-apply-mappartitions-to-dataframe-generated-from-carboncontext-tp14565p15277.html Sent from the Apache CarbonData Dev Mailing List archive mailing list archive at Nabble.com. |
|
|
Hi
I think you can debug in windows by adding some debug parameter when start spark-shell in linux. This is what called remote debug. I tried this method when I use windows, hope my idea can help you. Regards. Chenerlu. |
|
|
In reply to this post by Erlu Chen
i run this on yarn-client mode
孙而焓【FFCS研究院】
|
|
|
Hi
can you share me your test steps for reproducing this issue ? I mean completed test steps. Thanks. Chenerlu. |
|
|
In reply to this post by 孙而焓
modify carboncontext.scala file
adding @transient to two member variables and problem solved @transient val sc: SparkContext, @transient val hiveClientInterface = metadataHive
孙而焓【FFCS研究院】
|
Re: can't apply mappartitions to dataframe generated from carboncontext
|
|
Hi ,
It is great to hear that you solved this issue. Can you submit a PR for your changes Regards, Ravindra On 12 July 2017 at 14:42, Mic Sun <[hidden email]> wrote: > modify carboncontext.scala file > adding @transient to two member variables and problem solved > @transient > val sc: SparkContext, > > @transient > val hiveClientInterface = metadataHive > > > > ----- > FFCS研究院 > -- > View this message in context: http://apache-carbondata-dev- > mailing-list-archive.1130556.n5.nabble.com/can-t-apply- > mappartitions-to-dataframe-generated-from-carboncontext-tp14565p18068.html > Sent from the Apache CarbonData Dev Mailing List archive mailing list > archive at Nabble.com. > -- Thanks & Regards, Ravi |
«
Return to Apache CarbonData Dev Mailing List archive
|
1 view|%1 views
| Free forum by Nabble | Edit this page |