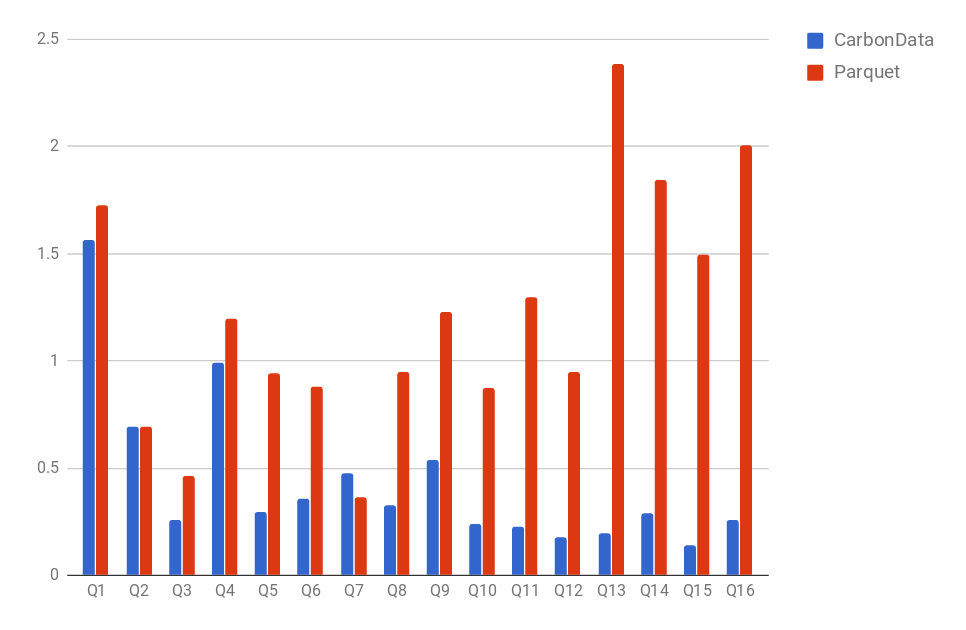
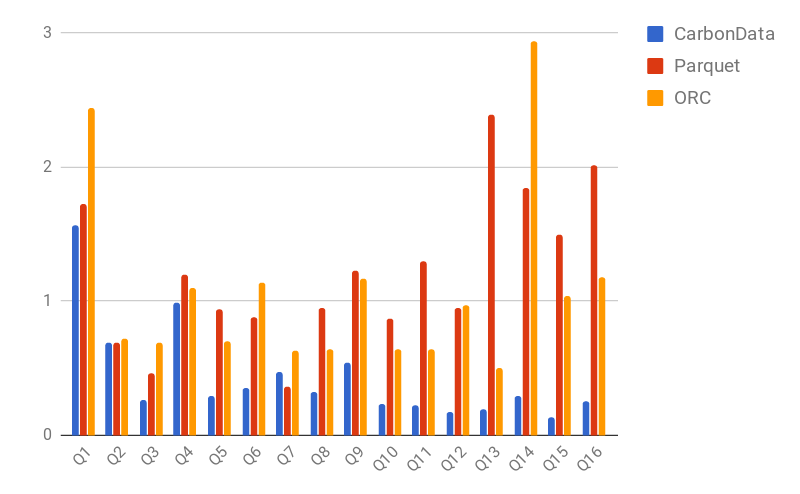
Hi Liang,
We went through the documentation of Presto and there were some issues with
Presto 0.166 version which were resolved in later versions. There is a lot
of performance improvement in 0.166 and 0.179 as the ways joins are
interpreted in Presto are different from 0.166. Please see below for two
most important reasons why we choose to ran it on 0.179.
1. Fixed issue which could cause incorrect results when processing
dictionary encoded data. If the expression can fail on bad input, the
results from filtered-out rows containing bad input may be included in the
query output.
2. The order in which joins are executed in a query can have a significant
impact on the query’s performance. The aspect of join ordering that has the
largest impact on performance is the size of the data being processed and
passed over the network. If a join is not a primary key-foreign key join,
the data produced can be much greater than the size of either table in the
join– up to |Table 1| x |Table 2| for a cross join. If a join that produces
a lot of data is performed early in the execution, then subsequent stages
will need to process large amounts of data for longer than necessary,
increasing the time and resources needed for the query causing query
failure. This issue has been fixed in the presto-version 11.3. Release
0.178 onwards.
Thanks and regards
Bhavya
On Sun, Jul 2, 2017 at 10:41 AM, Liang Chen <
[hidden email]> wrote:
> Hi Bhavya
>
> Currently, 1.2.0 propose to support presto version with 0.166.
> Is there any performance difference between 0.179 and 0.166?
>
> Regards
> Liang
>
>
> 2017-07-01 13:12 GMT+08:00 Bhavya Aggarwal <
[hidden email]>:
>
> > Hi,
> >
> > Please find the configuration setting that we used attached with this
> > email , we are running Presto Server 0.179 for our testing.
> >
> > Thanks and regards
> > Bhavya
> >
> > On Fri, Jun 30, 2017 at 8:23 AM, linqer <
[hidden email]> wrote:
> >
> >> Can you give me your all configuration files (etc/) of coordinate and
> >> worker,
> >> What configuration tuning did you make for carbondata?
> >>
> >> A lot of scenes in our company are using Presto,I have tested presto
> read
> >> orc vs carbondata , Carbondata is clearly inferior to Orc;
> >>
> >> During the testing, for performance reasons, we used replica join in
> >> particular, and we increased the JVM codecache size. but these are
> equally
> >> fair to both ORC and carbondata
> >>
> >> Carbondata_vs_ORC_on_Presto_Benchmark_testing.docx
> >> <
http://apache-carbondata-dev-mailing-list-archive.1130556.n> >> 5.nabble.com/file/n16849/Carbondata_vs_ORC_on_Presto_Benchma
> >> rk_testing.docx>
> >>
> >>
> >>
> >>
> >>
> >>
> >> --
> >> View this message in context:
http://apache-carbondata-dev-m> >> ailing-list-archive.1130556.n5.nabble.com/DISCUSSION-CarbonD
> >> ata-Integration-with-Presto-tp16793p16849.html
> >> Sent from the Apache CarbonData Dev Mailing List archive mailing list
> >> archive at Nabble.com.
> >>
> >
> >
>